
مقدمه
یادگیری عمیق و شبکههای عصبی حاصل یک جهش ناگهانی در علم نیستند، بلکه نتیجهی دههها تلاش، آزمونوخطا، شکست و پیشرفت تدریجی در درک نحوه یادگیری ماشینها از دادهها هستند. از مدلهای سادهی الهامگرفته از نورونهای زیستی گرفته تا معماریهای عمیق و پیچیدهی امروزی، این مسیر تکاملی نقش تعیینکنندهای در شکلگیری هوش مصنوعی مدرن داشته است.
درک صحیح یادگیری عمیق تنها با شناخت الگوریتمهای امروزی ممکن نیست؛ بلکه نیازمند آشنایی با ریشههای تاریخی، مفاهیم بنیادی، ساختارهای ریاضی و چالشهایی است که در طول زمان باعث تحول این حوزه شدهاند. مفاهیمی مانند پرسپترون، پسانتشار خطا، توابع فعالسازی، بهینهسازی، تنظیمپذیری و مقابله با بیشبرازش، هرکدام حلقهای از این زنجیره تکاملی هستند.
در این متن، سیر تکامل شبکههای عصبی از نخستین مدلهای مفهومی تا چارچوبهای پیشرفته یادگیری عمیق بررسی میشود. هدف این است که خواننده نهتنها با اجزای فنی شبکههای عصبی آشنا شود، بلکه تصویری منسجم از «چرایی» و «چگونگی» پیشرفت این حوزه به دست آورد و بتواند مفاهیم امروزی را در بستر تاریخی و علمی خود درک کند.
تاریخچه و سیر تکامل شبکههای عصبی: از رویا تا واقعیت
شبکههای عصبی (Neural Networks) در واقع آجرهای سازندهی پیشرفتهای شگفتانگیز امروز در حوزهی یادگیری عمیق هستند. یک شبکه عصبی را میتوان به عنوان یک واحد پردازش ساده در نظر گرفت که به صورت انبوه و موازی عمل میکند و قادر است دانش را ذخیره کرده و از آن برای انجام پیشبینیها استفاده کند.
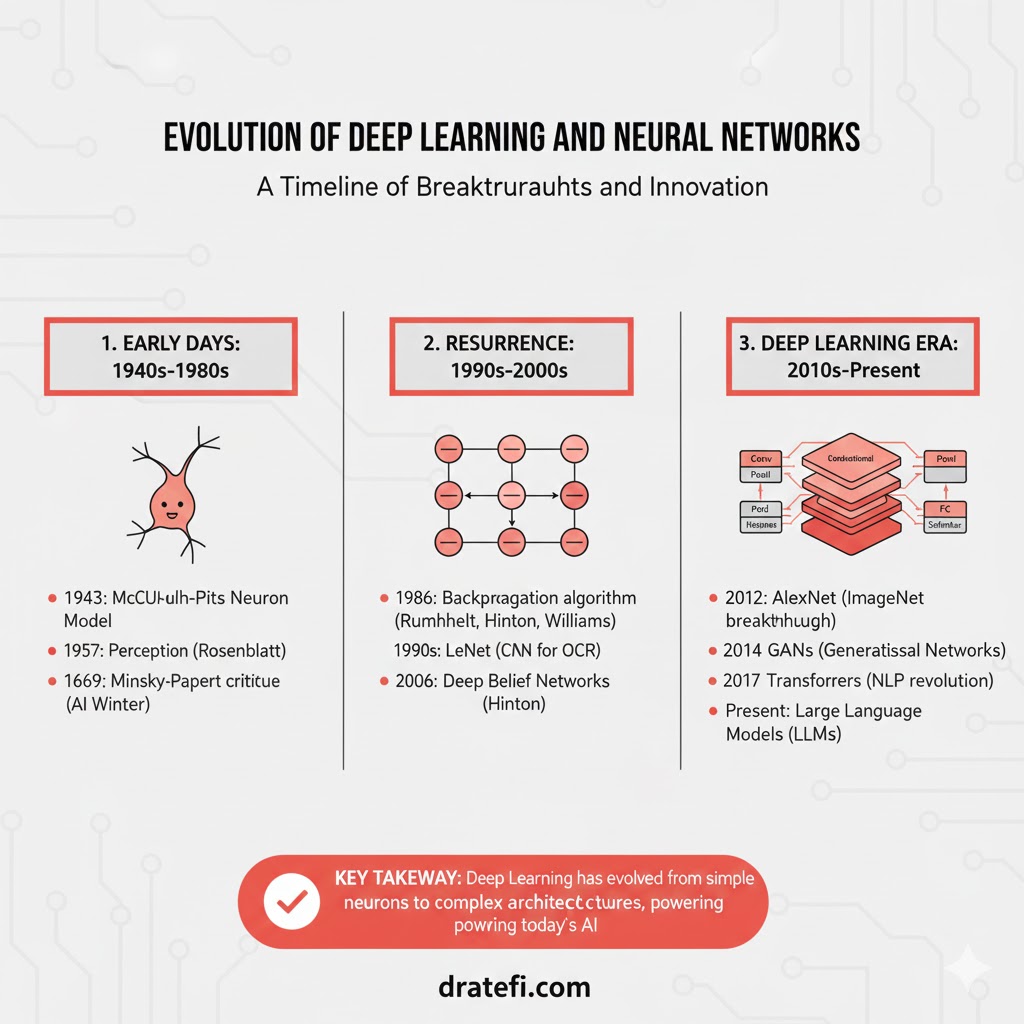
عصر پیشگامان: مدل مککالک و پیتس (۱۹۴۳)
وارن مککالک و والتر پیتس، پیشگامان این حوزه بودند که در سال ۱۹۴۳ مقالهای درباره مدلی با دو ورودی و یک خروجی نوشتند. ویژگیهای این مدل اولیه عبارت بود از:
- یک نورون تنها زمانی فعال میشد که یکی از ورودیها فعال باشد.
- وزنها برای هر ورودی با هم برابر بودند.
- خروجی مدل به صورت باینری (صفر یا یک) بود.
- یک سطح آستانه مشخص (Threshold) وجود داشت که با جمع زدن مقادیر ورودی محاسبه میشد تا خروجی نهایی مشخص شود.
۲. قانون هب و انعطافپذیری مغز (۱۹۴۹)
دونالد هب در کتاب خود با عنوان سازماندهی رفتار، این ایده را مطرح کرد که اتصالات مغز به طور مداوم در پاسخ به تغییر وظایف تغییر میکنند. این قانون به این معناست که ارتباط بین دو نورون زمانی که هر دو با هم فعال باشند، تقویت میشود. این مفهوم الهامبخش ساخت مدلهای محاسباتی برای سیستمهای یادگیرنده و تطبیقی شد.
ظهور پرسپترون (۱۹۵۸)
پس از ۱۵ سال، پرسپترون (Perceptron) توسط روزنبلات معرفی شد. پرسپترون سادهترین نوع شبکه عصبی است که دادهها را به صورت خطی به دو دسته تقسیم میکند. روزنبلات از روش آزمون و خطا برای تغییر وزنها و یادگیری مدل استفاده کرد.
دوران رکود یا زمستان اول (۱۹۶۹)
تحقیقات در این زمینه برای ۱۵ سال به بنبست رسید. دو ریاضیدان به نامهای ماروین مینسکی و سیمور پاپرت تحلیلهایی منتشر کردند که نشان میداد:
- پرسپترون قادر به حل مسائل ساده اما غیرخطی مانند تابع XOR نیست.
- کامپیوترهای آن زمان قدرت پردازش کافی برای مدیریت شبکههای عصبی بزرگ را نداشتند.
رنسانس شبکههای عصبی و انتشار رو به عقب (۱۹۸۶)
در سال ۱۹۸۶، با معرفی الگوریتم انتشار رو به عقب (Back-propagation) توسط روملهارت، هینتون و ویلیامز، نسل دوم شبکههای عصبی آغاز شد. این الگوریتم توانست مشکلاتی مثل تابع XOR را حل کند و به محبوبترین روش برای آموزش پرسپترونهای چندلایه تبدیل شود.
شباهت با مغز انسان: یادگیری و تطبیقپذیری
یک شبکه عصبی به این دلیل با مغز مقایسه میشود که دانش را از طریق یک فرآیند یادگیری از محیط خود کسب میکند. سپس، قدرت اتصالهای داخلی که به عنوان وزنهای سیناپسی شناخته میشوند، برای ذخیره این دانش به کار میروند. در طول این فرآیند، وزنها به شکلی منظم تغییر میکنند تا مدل به هدف نهایی خود برسد.
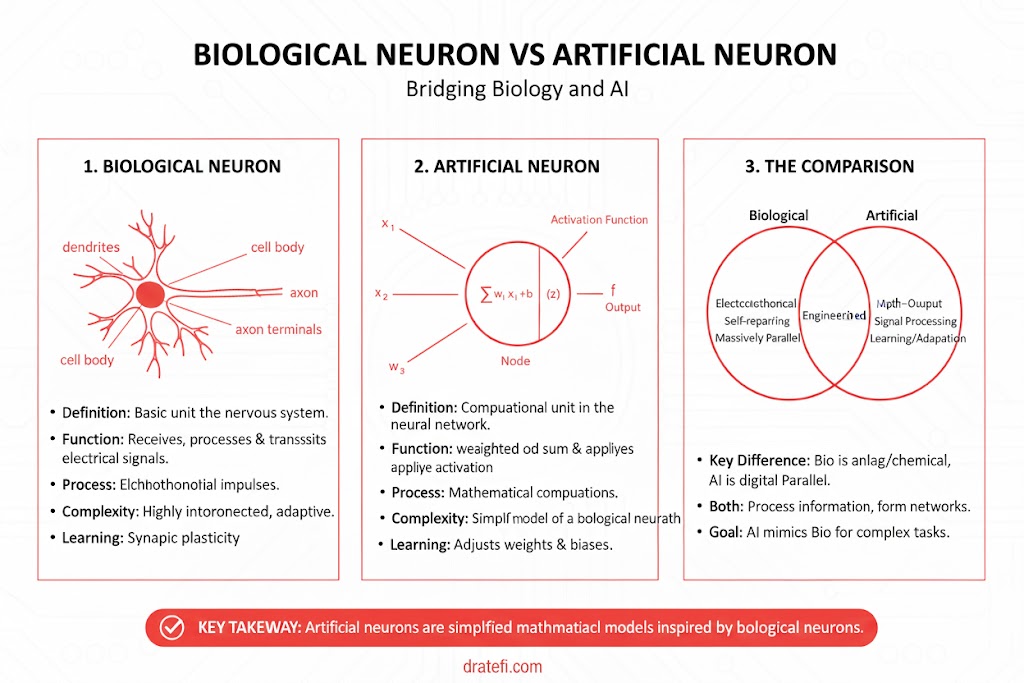
دلایل اصلی این شباهت عبارتند از:
- پردازش موازی غیرخطی: این سیستمها مانند مغز به صورت غیرخطی و موازی عمل میکنند و محاسباتی مثل تشخیص الگو و درک محیط را با سرعت بالا انجام میدهند.
- عملکرد عالی در دادههای پیچیده: به دلیل ماهیت غیرخطی، این شبکهها در حوزههایی مثل تشخیص گفتار، صدا و تصویر که ورودیهای آنها ذاتا غیرخطی هستند، بسیار موفق عمل میکنند.
معماری و اجزای پرسپترون تکلایه (SLP)
در یک SLP، یک لایه از وزنها وظیفه اتصال مستقیم ورودیها به خروجی را بر عهده دارد. این ساختار نه تنها برای حل مسائل ساده کاربرد دارد، بلکه پایه و اساس درک مدلهای پیچیدهتر مانند پرسپترونهای چندلایه (MLP) است.
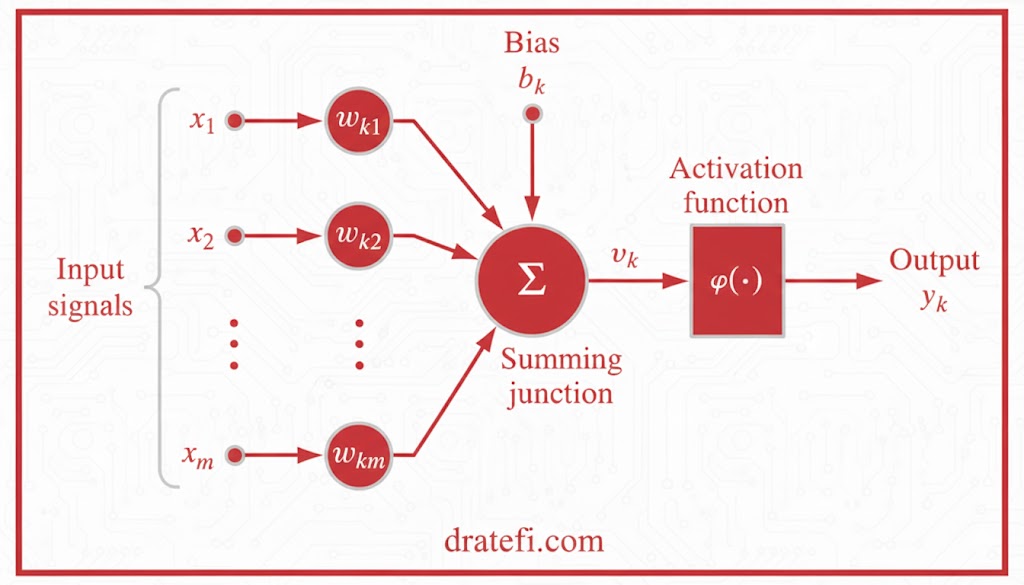
اجزای اصلی مدل:
- وزنهای سیناپسی(w): شبکه دارای m وزن است که به عنوان لینکهای اتصالی بین لایهها عمل میکنند. این پارامترها تعیین میکنند که هر ویژگی (Feature) ورودی چقدر در پیشبینی نهایی اهمیت دارد.
- تابع جمعکننده(Adder Function): در این بخش، هر یک از ویژگیهای ورودی در وزن سیناپسی متناظر خود ضرب شده و با هم جمع میشوند.
- بایاس(b): بایاس به عنوان یک تبدیل آفین (Affine Transformation) روی خروجی تابع جمعکننده عمل میکند تا انعطافپذیری مدل افزایش یابد.
ریاضیات پشت پرسپترون: میدان محلی القا شده
خروجی حاصل از ترکیب ورودیها، وزنها و بایاس را میدان محلی القا شده (Induced Local Field) مینامند که با v نشان داده میشود. فرمول محاسباتی آن به شرح زیر است:
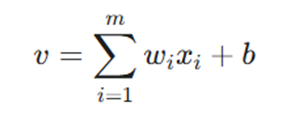
در این معادله:
- xi: نشاندهنده ورودیهای شبکه است.
- wi: وزنهای اختصاص یافته به هر ورودی هستند.
- b: مقدار بایاس اعمال شده برای انتقال خطی مدل است.
نکته کلیدی در مدلسازی
در یادگیری عمیق، درک این محاسبات پایه بسیار حیاتی است؛ زیرا مدلهای بزرگ در واقع مجموعهای از همین محاسبات در مقیاس بسیار وسیع هستند SLP. با وجود سادگی، مفهوم یادگیری تطبیقی را با تغییر دادن همین وزنها (w) برای رسیدن به هدف مطلوب نشان میدهد.
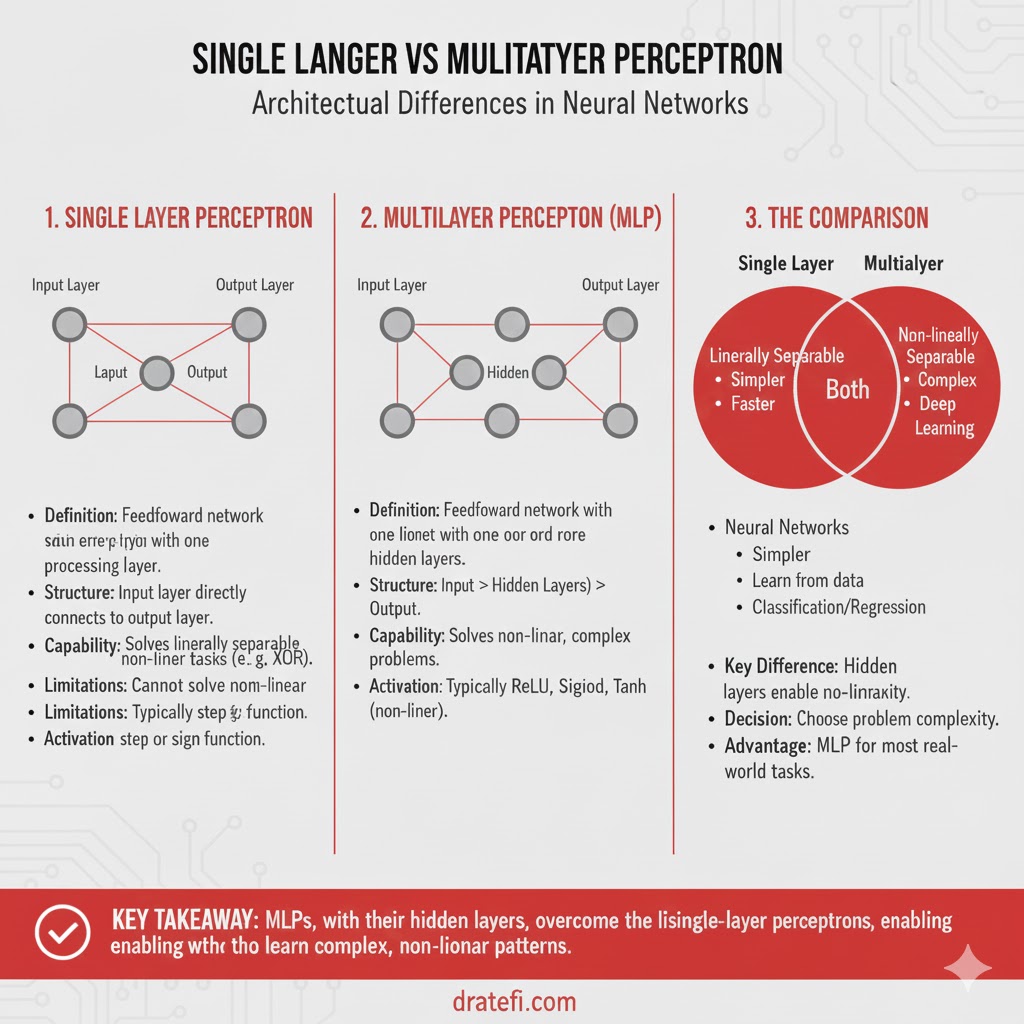
پرسپترون چندلایه(MLP): معماری شبکههای عصبی عمیق
یک پرسپترون چندلایه برخلاف مدل تکلایه، از توالی چندین لایه تشکیل شده است که هر لایه به طور کامل به لایه بعدی متصل (Fully Connected) میباشد. برای اینکه یک معماری به عنوان “عمیق” شناخته شود، لازم است چندین لایه پنهان (Hidden Layers) بین لایههای ورودی و خروجی قرار گیرند.
ساختار لایهها در MLP
یک شبکه MLP شامل سه نوع لایه اصلی است:
- لایه ورودی: تعداد نورونها در این لایه دقیقاً برابر با تعداد ویژگیها (Attributes) یا ابعاد دیتاست شماست.
- لایههای پنهان: جادوی اصلی یادگیری اینجا اتفاق میافتد. هر لایه شامل چندین نورون است که از طریق لینکهای وزنی با هم در ارتباط هستند.
- لایه خروجی: تعداد نورونهای این لایه برابر با تعداد کلاسها یا خروجیهای مورد نظر در دیتاست شماست.
فرمولبندی ریاضی و معرفی متغیرها
در یک شبکه چندلایه، خروجی هر نورون به عنوان ورودی برای نورونهای لایه بعدی عمل میکند. اگر بخواهیم محاسبات یک نورون در لایه l را بنویسیم، فرمول به صورت زیر گسترش مییابد:
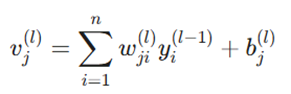
معرفی متغیرها:
- vj^ (l): میدان محلی القا شده (Induced Local Field) برای نورون j در لایه l.
- wji^ (l): وزن سیناپسی که نورون i از لایه قبلی را به نورون j در لایه فعلی متصل میکند.
- yi^ (l-1): سیگنال خروجی (یا ورودی) که از لایه قبلی (l-1) صادر شده است.
- bj^ (l): مقدار بایاس اختصاصی برای نورون j در لایه l که وظیفه تبدیل آفین را بر عهده دارد.
- n: تعداد کل نورونها در لایه قبلی.
چرا MLP برای یادگیری عمیق ضروری است؟
در مدلهای MLP، هر لایه پنهان ویژگیهای سطح بالاتری از دادههای لایه قبل را استخراج میکند. این ساختار سلسلهمراتبی به شبکه اجازه میدهد تا مسائل غیرخطی (مانند تابع XOR) را که پرسپترون تکلایه در حل آنها ناتوان بود، به راحتی پردازش و حل کند.
مقداردهی اولیه پارامترها (Initialization of the parameters)
مقداردهی اولیه پارامترها، یعنی وزنها (Weights) و بایاسها (Biases)، نقش بسیار مهمی در تعیین خروجی و کیفیت نهایی مدل ایفا میکند. ادبیات و منابع علمی گستردهای در زمینه استراتژیهای مختلف مقداردهی اولیه وجود دارد.
یک استراتژی مناسب برای مقداردهی اولیه تصادفی (Random Initialization) میتواند از گرفتار شدن مدل در کمینههای محلی (Local Minima) جلوگیری کند. مشکل کمینه محلی زمانی رخ میدهد که شبکه در سطح خطای (Error Surface) خود گیر کرده و در حین آموزش، دیگر به سمت پایین حرکت نمیکند؛ حتی اگر هنوز ظرفیت یادگیری در شبکه باقی مانده باشد.
انجام آزمایش با استفاده از استراتژیهای مختلف مقداردهی اولیه، خارج از محدوده این تحقیق است. با این حال، انتخاب استراتژی مقداردهی باید متناسب با تابع فعالسازی (Activation Function) مورد استفاده انجام شود.
۱. مقداردهی برای تابع فعالسازی Tanh
برای تابع فعالسازی tanh، بازه مقداردهی اولیه باید به صورت زیر باشد:
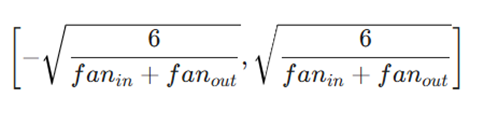
۲. مقداردهی برای تابع فعالسازی Sigmoid
به همین ترتیب، برای تابع فعالسازی sigmoid، بازه مقداردهی اولیه باید به این صورت در نظر گرفته شود:
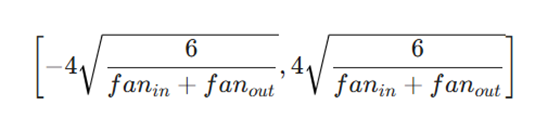
معرفی متغیرهای فرمول
در فرمولهای فوق، پارامترهای کلیدی زیر برای تعیین بازه تصادفی استفاده میشوند:
- fanin: تعداد واحدهای (نورونهای) موجود در لایه (i-1) یا همان لایه قبلی.
- fanout: تعداد واحدهای (نورونهای) موجود در لایه i یا همان لایه فعلی.
نتیجهگیری: استفاده از این استراتژیهای مقداردهی اولیه تضمین میکند که اطلاعات در مراحل ابتدایی آموزش، به درستی به سمت بالا (لایه خروجی) و به سمت عقب (از طریق انتشار رو به عقب) در شبکه منتشر شوند.
تابع فعال سازی
در دنیای یادگیری عمیق، توابع فعالسازی (Activation Functions) نقش کلیدی در غیرخطی کردن مدل و توانمندسازی آن برای یادگیری الگوهای پیچیده ایفا میکنند. تابع فعالسازی، خروجی یک نورون را بر اساس میدان محلی القا شده (v) به صورت زیر تعریف میکند:
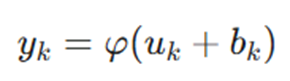
در این فرمول:
- (.)φ : نشاندهنده تابع فعالسازی است.
- uk: مجموع حاصلضرب ورودیها در وزنها.
- bk: مقدار بایاس (Bias) مربوط به نورون.
در ادامه، رایجترین توابع فعالسازی، فرمولها و کاربردهای آنها را بررسی میکنیم:
۱. تابع آستانه (Threshold Function)
این تابع سادهترین نوع فعالساز است که خروجی آن به صورت صفر و یک (باینری) تعیین میشود.
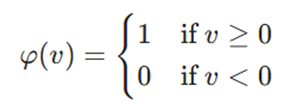
در این فرمول، v همان ورودی خالص نورون است.
- ویژگی: نورون یا کاملاً فعال است (۱) یا کاملاً غیرفعال (۰).
- چالش: این تابع مشتقپذیر نیست، که این ویژگی برای الگوریتم انتشار رو به عقب (Back-propagation) بسیار حیاتی است.
- کاربرد: بیشتر در شبکههای عصبی اولیه مانند پرسپترون ساده برای مسائل طبقهبندی خطی استفاده میشد.
۲. تابع سیگموئید (Sigmoid Function)
تابع سیگموئید یک تابع لجستیک است که خروجی آن در بازه بین ۰ و ۱ محدود شده است.
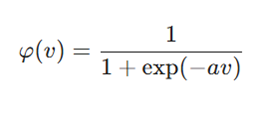
در این فرمول:
- a: پارامتر شیب تابع است.
- v: ورودی نورون.
- ویژگی: این تابع پیوسته و مشتقپذیر است و ماهیتی غیرخطی دارد. تغییرات کوچک در وزنها و بایاس باعث تغییرات کوچک و نرم در خروجی میشود.
- کاربرد: در لایه خروجی مدلهای طبقهبندی دوتایی (Binary Classification) برای پیشبینی احتمال استفاده میشود.
۳. تابع تانژانت هیپربولیک (Hyperbolic Tangent Function)
این تابع شباهت زیادی به سیگموئید دارد، اما خروجی آن در بازه وسیعتری قرار میگیرد.
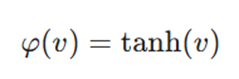
- ویژگی: بازه خروجی این تابع بین ۱- تا ۱+ است. این ویژگی باعث میشود میانگین خروجی لایهها به صفر نزدیکتر شود که آموزش را پایدارتر میکند.
- کاربرد: معمولاً در لایههای پنهان شبکههای عصبی چندلایه استفاده میشود.
۴. تابع فعالسازی خطی اصلاحشده (ReLU)
توابع ReLU تقریب نرمی برای مجموع بسیاری از واحدهای لجستیک هستند و بردارهای فعالیت پراکنده (Sparse) تولید میکنند.
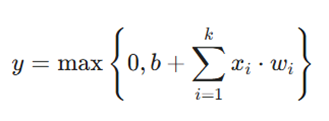
در این فرمول:
- xi: ورودیهای مدل.
- wi: وزنهای مربوط به ورودیها.
- b: مقدار بایاس
- کاربرد: محبوبترین تابع برای لایههای پنهان در شبکههای عصبی عمیق (CNN و MLP) به دلیل سرعت بالای محاسبات و رفع مشکل ناپدید شدن گرادیان.
۵. تابع مکساوت (Maxout Function)
در سال ۲۰۱۳، گودفلو (Goodfellow) دریافت که شبکه Maxout یک همراه طبیعی برای تکنیک Dropout است.
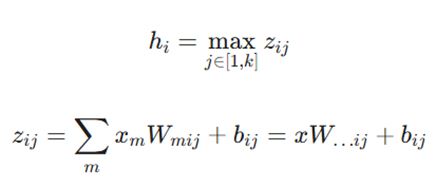
در این فرمول:
- W… ij: بردار میانگین ورودی است که از ماتریس W ∈ R^(m ✕ n ✕ k) استخراج میشود.
- k: تعداد قطعات (Pieces) مورد استفاده در شبکه Maxout است که به آن واحدهای میانی نیز میگویند.
- ویژگی: واحدهای Maxout بهینهسازی از طریق Dropout را تسهیل کرده و دقت تکنیک میانگینگیری مدل را بهبود میدهند. این تابع یک تقریب خطی تکهای (Piece-wise Linear) از هر تابع محدب دلخواه میسازد.
- کاربرد: در شبکههایی که از Dropout سنگین استفاده میکنند برای بهبود دقت و سرعت آموزش.
الگوریتم انتشار رو به عقب (Backpropagation Algorithm)
الگوریتم انتشار رو به عقب ابزاری حیاتی برای آموزش شبکههای عصبی پیشخور (Feed-forward) یا همان پرسپترونهای چندلایه است. این الگوریتم در واقع روشی برای کمینه کردن تابع هزینه (Cost Function) از طریق تغییر هوشمندانه وزنها و بایاسها در کل شبکه است.
برای اینکه مدل یاد بگیرد و پیشبینیهای دقیقتری ارائه دهد، تعدادی دوره آموزشی (Epoch) اجرا میشود. در هر دوره، خطایی که توسط تابع هزینه در لایه خروجی تعیین شده است، به کمک روش گرادیان کاهشی (Gradient Descent) به سمت عقب در شبکه منتشر میشود تا زمانی که خطا به مقدار بهینه و به اندازه کافی کوچک برسد.
روشهای اجرای گرادیان کاهشی (Gradient Descent)
گرادیان کاهشی تعیین میکند که پارامترهای مدل با چه استراتژی و سرعتی آپدیت شوند. سه روش اصلی برای این کار وجود دارد:
۱. گرادیان کاهشی مینی-بچ (Mini-Batch Gradient Descent)
در این روش، دادههای آموزش به گروههای کوچکی تقسیم میشوند. برای مثال، در یک مینی-بچ با اندازه ۱۰۰، تعداد ۱۰۰ نمونه آموزشی به الگوریتم یادگیری نشان داده شده و وزنها بر اساس میانگین خطای این ۱۰۰ نمونه آپدیت میشوند.
- روند اجرا: پس از اینکه تمام مینی-بچها به صورت متوالی به شبکه ارائه شدند، میانگین سطوح دقت و هزینههای آموزش برای هر دوره (Epoch) محاسبه میگردد.
- کاربرد: این روش محبوبترین گزینه در یادگیری عمیق مدرن است؛ زیرا تعادلی بین سرعت محاسباتی و پایداری در همگرایی ایجاد میکند.
- استفاده از مینی-بچ باعث میشود که از توان پردازشی GPUها به بهترین شکل استفاده شود.
۲. گرادیان کاهشی تصادفی (Stochastic Gradient Descent – SGD)
این روش در پردازشهای آنلاین و آنی (Real-time On-line) کاربرد دارد. در اینجا، پارامترها بلافاصله پس از ارائه تنها یک نمونه آموزشی آپدیت میشوند.
- روند اجرا: میانگین سطوح دقت و هزینههای آموزش در پایان هر دوره برای کل مجموعه داده محاسبه میشود.
- کاربرد: زمانی که دادهها به صورت جریانی (Stream) وارد میشوند یا حجم دادهها آنقدر زیاد است که امکان بارگذاری همزمان آنها وجود ندارد.
- SGD نویز زیادی دارد که میتواند به مدل کمک کند تا از کمینههای محلی (Local Minima) فرار کند، اما مسیر همگرایی آن بسیار پر نوسان است.
۳. گرادیان کاهشی دستهای کامل (Full Batch Gradient Descent)
در این متد، تمام نمونههای آموزشی موجود در دیتاست به صورت یکجا به الگوریتم یادگیری نشان داده شده و سپس تنها یک بار وزنها آپدیت میشوند.
- کاربرد: این روش برای مجموعهدادههای کوچک که کاملاً در حافظه (RAM) جا میشوند مناسب است.
- اگرچه مسیر حرکت این روش به سمت نقطه بهینه بسیار مستقیم و پایدار است، اما برای دادههای حجیم به دلیل نیاز به حافظه بسیار زیاد و سرعت پایین، عملاً غیرقابل استفاده است.
فرمول بهینهسازی وزنها
در تمام روشهای فوق، آپدیت وزنها از فرمول کلی زیر پیروی میکند:
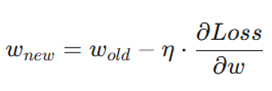
معرفی متغیرها:
- wnew: مقدار جدید وزن پس از اصلاح خطا.
- wold: مقدار فعلی وزن قبل از آپدیت.
- η (Learning Rate): نرخ یادگیری که تعیین میکند گامهای تغییر وزن چقدر بزرگ باشند.
توابع هزینه (Cost Function)
توابع هزینه متنوعی وجود دارند که در اینجا به برخی از نمونههای پرکاربرد اشاره میکنیم:
۱. تابع میانگین مربعات خطا (Mean Squared Error Function)
این تابع تفاوت بین مقدار پیشبینی شده و مقدار واقعی را به توان دو میرساند.
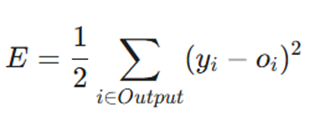
- متغیرها:
- yi: خروجی پیشبینی شده توسط مدل.
- oi: خروجی واقعی (هدف).
- کاربرد: این تابع استاندارد اصلی در مسائل رگرسیون (پیشبینی مقادیر عددی پیوسته مانند قیمت مسکن یا دمای هوا) است.
۲. تابع آنتروپی متقاطع (Cross-Entropy Function)
این تابع میزان تفاوت بین دو توزیع احتمال (توزیع پیشبینی شده توسط مدل و توزیع واقعی) را محاسبه میکند.
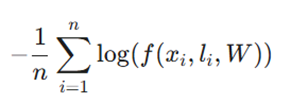
- متغیرها:
- xi: ورودی مدل.
- li: برچسب (لیبل) واقعی.
- W: پارامترهای وزن مدل.
- n: اندازه دسته آموزشی. (Training-batch size)
- این تابع جریمههای بسیار سنگینی برای پیشبینیهای غلطی که با اطمینان بالا انجام شدهاند، در نظر میگیرد.
- کاربرد: پرکاربردترین تابع در مسائل طبقهبندی (مانند تشخیص تصویر یا تحلیل احساسات متن).
۳. تابع زیان منفی لگاریتم درستنمایی (Negative Log-Likelihood Loss – NLL)
این تابع هزینه در تمامی آزمایشهای گزارش حاضر مورد استفاده قرار گرفته است.
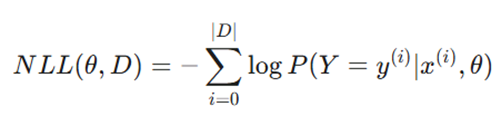
- متغیرها:
- y^ (i): مقدار خروجی (برچسب واقعی).
- x^ (i): مقدار ورودی ویژگی (Feature Input).
- D: مجموعه دادههای آموزشی.
- NLL به دنبال حداکثر کردن احتمال مشاهده دادههای واقعی تحت پارامترهای مدل است. زمانی که از خروجی Softmax در لایه آخر استفاده میشود، ترکیب آن با NLL دقیقاً معادل آنتروپی متقاطع خواهد بود.
- کاربرد: این تابع در مدلهای احتمالی و به ویژه در شبکههای عصبی عمیق برای طبقهبندی چندکلاسه کاربرد وسیعی دارد.
نرخ یادگیری (Learning Rate)
نرخ یادگیری پارامتری است که میزان تغییرات وزنها را از یک تکرار (Iteration) به تکرار دیگر کنترل میکند. به عنوان یک قاعده کلی، نرخهای یادگیری کوچکتر پایدارتر در نظر گرفته میشوند، اما باعث سرعت پایین یادگیری میشوند. از سوی دیگر، نرخهای یادگیری بالاتر میتوانند ناپایدار باشند و باعث نوسانات شدید و خطاهای محاسباتی شوند، اما سرعت یادگیری را افزایش میدهند.
فرمول اصلاح وزن:
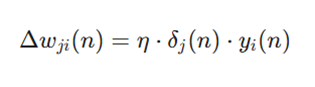
- معرفی متغیرها:
- Δwji (n): مقدار اصلاح یا تغییر وزن در تکرار n-اُم.
- η: پارامتر نرخ یادگیری (Learning Rate).
- δj(n): گرادیان محلی (Local Gradient) برای نورون j در تکرار. n
- yi(n): سیگنال ورودی به نورون j از لایه قبلی در تکرار. n
- کاربرد: در تمام الگوریتمهای بهینهسازی مبتنی بر گرادیان برای تنظیم سرعت همگرایی مدل استفاده میشود.
- یافتن مقدار بهینه η یکی از بزرگترین چالشهای آموزش شبکه است؛ امروزه اغلب از نرخ یادگیری تطبیقی استفاده میشود که در طول آموزش مقدار خود را تغییر میدهد.
گشتاور (Momentum)
(Momentum) نوعی اینرسی یا لختگی برای شبکه فراهم میکند تا بتواند از کمینههای محلی (Local Minima) فرار کند. ایده اصلی ساده است: کسری از آپدیت قبلی وزن را به آپدیت فعلی اضافه میکنیم؛ این کار به شبکه کمک میکند تا در چالههای کمینه محلی گیر نیفتد.
فرمول:
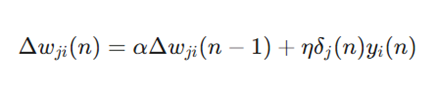
- معرفی متغیرها:
- Δwji (n): آپدیت فعلی وزن.
- Δwji (n-1): آپدیت وزن در مرحله قبلی.
- α: پارامتر (Momentum) که معمولاً عددی بین ۰ و ۱ است.
- η , δ , y: همان متغیرهای نرخ یادگیری و گرادیان.
- کاربرد: برای تسریع آموزش و عبور از نواحی تخت در سطح خطا (Error Surface) در الگوریتمهایی مثل SGD کاربرد دارد.
تابع سافتمکس (Softmax)
سافتمکس یک تابع انتقال عصبی (Neural Transfer Function) است که در واقع فرم تعمیمیافته تابع لجستیک محسوب میشود. این تابع در لایه خروجی پیادهسازی شده و بردارهای اعداد خام را به احتمالاتی تبدیل میکند که مجموع آنها دقیقاً برابر با ۱ است.
فرمول سافتمکس:
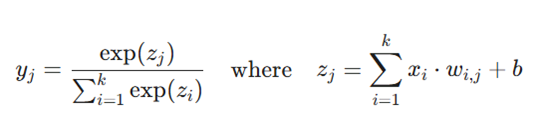
- معرفی متغیرها:
- yj: احتمال پیشبینی شده برای کلاس. j
- zj: مقدار ورودی خالص (Logit) برای نورون j قبل از اعمال سافتمکس.
- Σexp(z_i): مجموع مقادیر نمایی تمام نورونهای خروجی (برای نرمالسازی).
- کاربرد: تابع فعالساز نهایی در مسائل طبقهبندی چندکلاسه (Multi-class Classification) که خروجیهای متناقض (Exclusive) دارند.
- سافتمکس باعث میشود بزرگترین عدد در خروجی شبکه برجسته شود و به صورت یک توزیع احتمال معتبر ارائه گردد؛ به همین دلیل مکمل اصلی تابع زیان Cross-Entropy است.
مروری بر یادگیری عمیق (Overview of Deep Learning)
پیش از سال ۲۰۰۶، تلاشهای متعددی برای آموزش شبکههای عصبی پیشخور عمیق صورت گرفت که اغلب با شکست مواجه میشد. مشکل اصلی، بیشبرازش (Over-fitting) بود؛ وضعیتی که در آن خطای آموزش کاهش مییابد اما خطای اعتبارسنجی (روی دادههای دیده نشده) افزایش پیدا میکند.
یک شبکه عمیق معمولاً به معنای شبکه عصبی است که بیش از یک لایه پنهان دارد. بنجیو (Bengio) پیشنهاد میکند که نورونها در لایههای پنهان به عنوان آشکارساز ویژگی عمل میکنند که توسط لایههای پایینتر آموخته شدهاند. این ساختار سلسلهمراتبی باعث تعمیمپذیری بهتر مدل میشود.
امروزه، دو عامل حیاتی باعث موفقیت یادگیری عمیق شده است:
۱. قدرت محاسباتی: استفاده از واحدهای پردازش گرافیکی (GPU) برای محاسبات سنگین ماتریسی.
۲. رایانش ابری: خوشهبندی کامپیوترها و پردازش موازی برای کاهش زمان آموزش.
ماشین بولتزمن محدود (RBM) و شبکههای باور عمیق (DBN)
ماشین بولتزمن محدود (RBM) یک الگوریتم یادگیری بدون نظارت است که برای پیشآموزش شبکههای باور عمیق استفاده میشود. در یک RBM، ارتباط بین واحدهای پنهان در یک لایه قطع شده است (گراف دو بخشی) که یادگیری را بسیار سادهتر و موازی میکند.
در مدل شبکه باور عمیق (DBN)، خروجیهای فعالشده در یک لایه RBM به عنوان ورودی برای لایه بعدی در نظر گرفته میشوند. این فرآیند را میتوان یادگیریِ ویژگیهایِ ویژگیها نامید.
تکنیک Dropout:مقابله با بیشبرازش
Dropout یک تکنیک تنظیمکننده (Regularization) قدرتمند است که توسط هینتون (Hinton) معرفی شد. این روش از همسازگاری (Co-adaptation) بیش از حد ویژگیها جلوگیری میکند. در هر بار تکرار آموزش، بخشی از نورونها به صورت تصادفی خاموش میشوند، اما در زمان تست از کل شبکه با وزنهای مقیاسگذاری شده استفاده میشود.

اثبات ریاضی Dropout به عنوان یک روش مجموعهساز (Ensemble)
Dropout به صورت ریاضی معادل میانگینگیری از تعداد نمایی از مدلهای مختلف است.
۱. پیشبینی مجموعه:
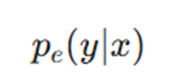
- پیشبینی حاصل از مجموعهای از مدلها با استفاده از میانگین هندسی.
۲. پیشبینی زیرمدل(Sub-model Prediction):
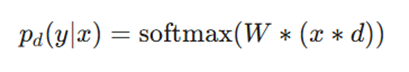
- pd(y|x): پیشبینی یک زیرمدل واحد.
- d: بردار باینری که تعیین میکند کدام ورودیها در طبقهبندی سافتمکس لحاظ شوند.
۳. فرمول کلی توزیع احتمال:
اگر N واحد وجود داشته باشد، 2 به توان N حالت ممکن برای بردار d وجود دارد:
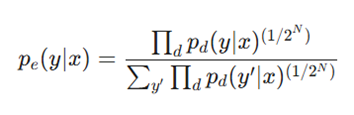
- y: کلاس هدف تکی.
- ‘y: بردار شاخص کلاسها.
۴. سادهسازی به تعریف سافتمکس:
طبق تعریف سافتمکس، عبارت فوق متناسب است با:
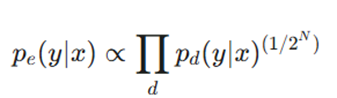
که در نهایت به فرم زیر ساده میشود:
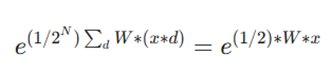
۵. توزیع نهایی پیشبینی:
برای بازنرمالسازی (Re-normalize) عبارت فوق، بر مجموع احتمالات تقسیم شده و توزیع نهایی حاصل میشود:
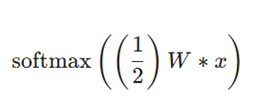
تکنیکهای مقابله با عدم توازن کلاسها (Techniques to deal with class imbalance)
مشکل عدم توازن کلاس زمانی رخ میدهد که یکی از کلاسها (کلاس اقلیت) در مقایسه با سایر کلاسها (کلاس اکثریت (Majority- به شدت کمتر از آنچه هست نمایش داده شود. این مسئله در دنیای واقعی اهمیت زیادی دارد، زیرا اشتباه در طبقهبندی کلاسهای اقلیت بسیار هزینهبر است؛ مانند تشخیص فعالیتهای غیرعادی نظیر کلاهبرداری یا نفوذ. تکنیکهای مختلفی برای مقابله با این مشکل وجود دارد که در ادامه توضیح داده شده است:
۱. روش SMOTE: تکنیک بیشنمونهبرداری مصنوعی کلاس اقلیت
یکی از رویکردهای گسترده برای حل این مشکل، بازنمونهبرداری (Resampling) از مجموعه داده است. این روش شامل پیشپردازش و متعادلسازی دادههای آموزشی از طریق تنظیم توزیع پیشین (Prior Distribution) برای کلاسهای اقلیت و اکثریت است. SMOTE یک رویکرد بیشنمونهبرداری (Over-sampling) است که در آن کلاس اقلیت با ایجاد نمونههای مصنوعی (Synthetic) تقویت میشود، به جای اینکه صرفاً از نمونهبرداری با جایگزینی استفاده شود.
پیشنهاد شده است که بیشنمونهبرداری ساده (با جایگزینی) نتایج را بهطور چشمگیری بهبود نمیبخشد و در کلاس اقلیت تمایل به بیشبرازش (Overfitting) دارد. در مقابل، الگوریتم SMOTE در فضای ویژگی — نه در فضای نمونههای اصلی — عمل میکند و با تولید نمونههای مصنوعی، به تعمیمپذیری (Generalization) مدل کمک میکند.
ایدهٔ این روش از تولید دادههای آموزشی اضافی — از طریق عملیات روی دادههای واقعی — الهام گرفته شده تا حجم داده برای بهبود پیشبینی افزایش یابد. در این الگوریتم:
۱. ابتدا k نزدیکترین همسایه برای هر نمونه از کلاس اقلیت شناسایی میشوند.
۲. سپس یکی از این همسایگان بهصورت تصادفی انتخاب میشود.
۳. فاصلهٔ آن با نمونهٔ اصلی محاسبه و در عددی تصادفی بین ۰ تا ۱ ضرب میشود.
۴. این مقدار به بردار ویژگی نمونهٔ اصلی اضافه میشود تا یک نمونهٔ مصنوعی جدید ایجاد شود.
۲. یادگیری حساس به هزینه در شبکههای عصبی (Cost-sensitive learning)
یادگیری حساس به هزینه روشی بسیار موثر برای رسیدگی به عدم توازن کلاس در مسائل طبقهبندی است. سه متد حساس به هزینه که مخصوص شبکههای عصبی هستند، توصیف شدهاند:
الف) ادغام توزیع پیشین کلاسها در لایهٔ خروجی شبکهٔ عصبی هنگام پردازش نمونههای دیدهنشده
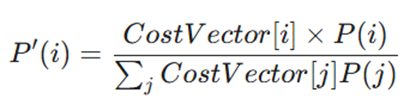
- متغیرها:
- P'(i): احتمال تعدیل شده برای کلاس i.
- CostVector[i]: هزینه نسبت داده شده به کلاس i.
- P(i): احتمال پیشین (Original Prior Probability) کلاس i.
ب) تنظیم نرخ یادگیری بر اساس هزینهها:
نرخهای یادگیری بالاتر باید به نمونههایی با هزینه اشتباه (Misclassification) بالاتر اختصاص یابد تا تاثیر بیشتری بر تغییرات وزن برای آن نمونهها داشته باشد:
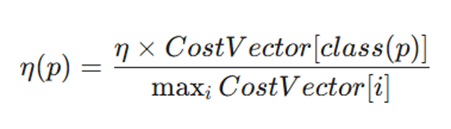
ج) اصلاح تابع میانگین مربعات خطا:
در نتیجه، یادگیری انجام شده توسط انتشار رو به عقب (Backpropagation)، هزینههای طبقهبندی اشتباه را به حداقل میرساند. تابع خطای جدید عبارت است از:
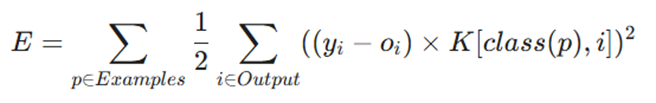
- متغیرها:
- K[i, j]: فاکتور هزینه (Cost Factor) بین کلاس واقعی i و کلاس پیشبینی شده j.
- yi: خروجی مطلوب (Target).
- oi: خروجی واقعی شبکه.
این تابع خطای جدید منجر به یک قانون دلتای جدید (New Delta Rule) برای بهروزرسانی وزنهای شبکه میشود:
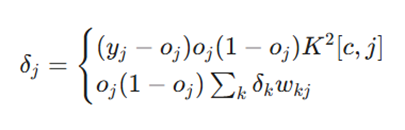
- توضیح: معادله اول نشاندهنده تابع خطا برای نورونهای خروجی و معادله دوم نشاندهنده تابع خطا برای نورونهای پنهان است.
جمع بندی
یادگیری عمیق نتیجهٔ تکامل تدریجی ایدههایی است که از مدلهای سادهٔ نورونی آغاز شد و با پیشرفت نظریهها، الگوریتمها و توان محاسباتی، به معماریهای پیچیده و قدرتمند امروزی رسید. بررسی این مسیر نشان میدهد موفقیت شبکههای عصبی تنها به افزایش تعداد لایهها بستگی ندارد؛ بلکه حاصل همافزایی مفاهیمی مانند توابع فعالسازی غیرخطی، الگوریتمهای بهینهسازی، روشهای منظمسازی و مدیریت هوشمند دادههاست.
در این فایل دیدیم که چگونه محدودیتهای پرسپترون تکلایه، زمینهساز ظهور شبکههای چندلایه و الگوریتم پسانتشار شد و چگونه چالشهایی مانند بیشبرازش، ناپدید شدن گرادیان و عدم توازن کلاسها با معرفی تکنیکهایی مانند Dropout، مقداردهی اولیه مناسب، بهینهسازهای پیشرفته و یادگیری حساس به هزینه تا حد زیادی برطرف شدند. همچنین نقش حیاتی مفاهیمی مانند Softmax، توابع زیان و نرخ یادگیری در آموزش پایدار شبکهها روشن شد.
در نهایت، درک عمیق یادگیری عمیق نیازمند نگاه سیستمی به کل این اجزا است. شبکههای عصبی مجموعهای از فرمولها و الگوریتمهای جداگانه نیستند، بلکه یک چارچوب منسجم یادگیری محسوب میشوند که هر جزء آن بر عملکرد نهایی تأثیر میگذارد. تسلط بر این مفاهیم بنیادی، پایهای محکم برای ورود به معماریهای پیشرفتهتر، پژوهشهای تخصصی و طراحی سیستمهای هوشمند در دنیای واقعی فراهم میکند.



