
مقدمه
شبکههای عصبی مصنوعی (ANN) با الهام از ساختار مغز انسان طراحی شدهاند و از گرههای متصلی به نام نورون برای حل مسائل پیچیده استفاده میکنند. همانطور که در مستندات شما ذکر شده، این لایهها و نورونها با همکاری یکدیگر ویژگیهای داده را استخراج کرده و پیشبینی نهایی را انجام میدهند.
برآورد تعداد نورونها (Estimation of Neurons) چیست؟
برآورد نورونها در شبکههای عصبی به معنای تعیین تعداد بهینهی نورونها در هر لایه از شبکه است. این مرحله در طراحی و آموزش شبکههای عصبی بسیار حیاتی است، زیرا تعداد نورونها تأثیر مستقیمی بر عملکرد مدل دارد. بر اساس مستندات شما، این فرآیند به تعادل میان دو چالش زیر کمک میکند:
تعداد کم نورونها(Underfitting):
اگر تعداد نورونها خیلی کم باشد، مدل نمیتواند پیچیدگی دادهها و الگوهای پنهان را به درستی درک کند.
تعداد زیاد نورونها(Overfitting):
اگر نورونها بیش از حد باشند، مدل به جای یادگیری، دادههای آموزشی را حفظ میکند و در مواجهه با دادههای جدید عملکرد ضعیفی خواهد داشت.
برای یافتن این تعداد بهینه، از روشهایی مانند آزمون و خطا، اعتبارسنجی متقاطع (Cross-validation) و تکنیکهای پیشرفتهای مثل هرس کردن (Pruning) استفاده میشود.
مطالعه موردی: برآورد نورونها برای مسئله دستهبندی دوتایی (Churn Prediction)
بیایید یک مسئله دستهبندی دوتایی (Binary Classification) را بررسی کنیم که در آن میخواهیم پیشبینی کنیم آیا مشتری از خدمات ما خارج میشود (Churn) یا خیر.
۱. تحلیل لایه ورودی (Input Layer)
در این مثال فرضی، ما ۴ متغیر ورودی (Input Variables) داریم. طبق قانون اصلی که در فایل شما ذکر شده است:
- تعداد نورونهای لایه ورودی دقیقاً با تعداد ویژگیهای دادههای ورودی برابر است.
- بنابراین، برای این شبکه، ما ۴ نورون در لایه ورودی خواهیم داشت.
۲. تحلیل لایههای پنهان (Hidden Layers)
در لایههای پنهان، هوش مدل شکل میگیرد. برای این مثال با ۸ مشاهده (Observation)، تعداد نورونهای لایههای پنهان باید به گونهای انتخاب شود که الگوهای این ۸ مورد را بدون حفظ کردن (Overfitting) یاد بگیرد.
۳. تحلیل لایه خروجی (Output Layer)
از آنجایی که این یک مسئله دستهبندی دوتایی (بله/خیر) است:
- طبق مستندات شما، برای دستهبندیهای دوگانی از تابع فعالسازی Sigmoid استفاده میشود.
- تعداد نورون در لایه خروجی برای این مسئله ۱ نورون خواهد بود که احتمالی بین ۰ تا ۱ را نشان میدهد.
مطالعه موردی : پیشبینی وفاداری مشتریان پلتفرم آنلاین
ما میخواهیم بدانیم مشتریانی مثل آرش یا سارا بر اساس رفتارشان، ماه آینده هم از ما خرید میکنند یا خیر.
۱. دادههای ورودی(متغیرهای مستقل – X ):
در لایه اول (L1)، ما ۴ ویژگی کلیدی را از دیتابیس استخراج کرده و به نورونها میدهیم:
- سابقه عضویت: چند سال است که کاربر ماست؟
- تعداد خرید اخیر: در یک ماه گذشته چند بار سفارش ثبت کرده؟
- میانگین امتیاز: به محصولات ما چه امتیازی (۱ تا ۵) داده است؟
- زمان آخرین بازدید: چند روز از آخرین باری که اپلیکیشن را باز کرده میگذرد؟
۲. جدول دادههای نمونه:
این دادههای خام قبل از ورود به شبکه، نرمالسازی میشوند (مثلاً سن یا تعداد خرید تبدیل به عددی بین ۰ و ۱ میشود).
| نام مشتری | تعداد خرید (ماه) | امتیازدهی | روز از آخرین بازدید | سابقه (سال) | وضعیت (ریزش/ماندگاری) |
| آرش | ۱ | ۲ | ۲۵ | ۴ | ۱ (احتمال ریزش بالا) |
| سارا | ۷ | ۵ | ۱ | ۲ | ۰ (مشتری وفادار) |
| امیر | ۲ | ۳ | ۱۵ | ۳ | ۱ (در خطر ریزش) |
| مریم | ۵ | ۴ | ۲ | ۶ | ۰ (وفادار) |
۳. تشریح ساختار شبکه عصبی[4, 5, 3, 2]
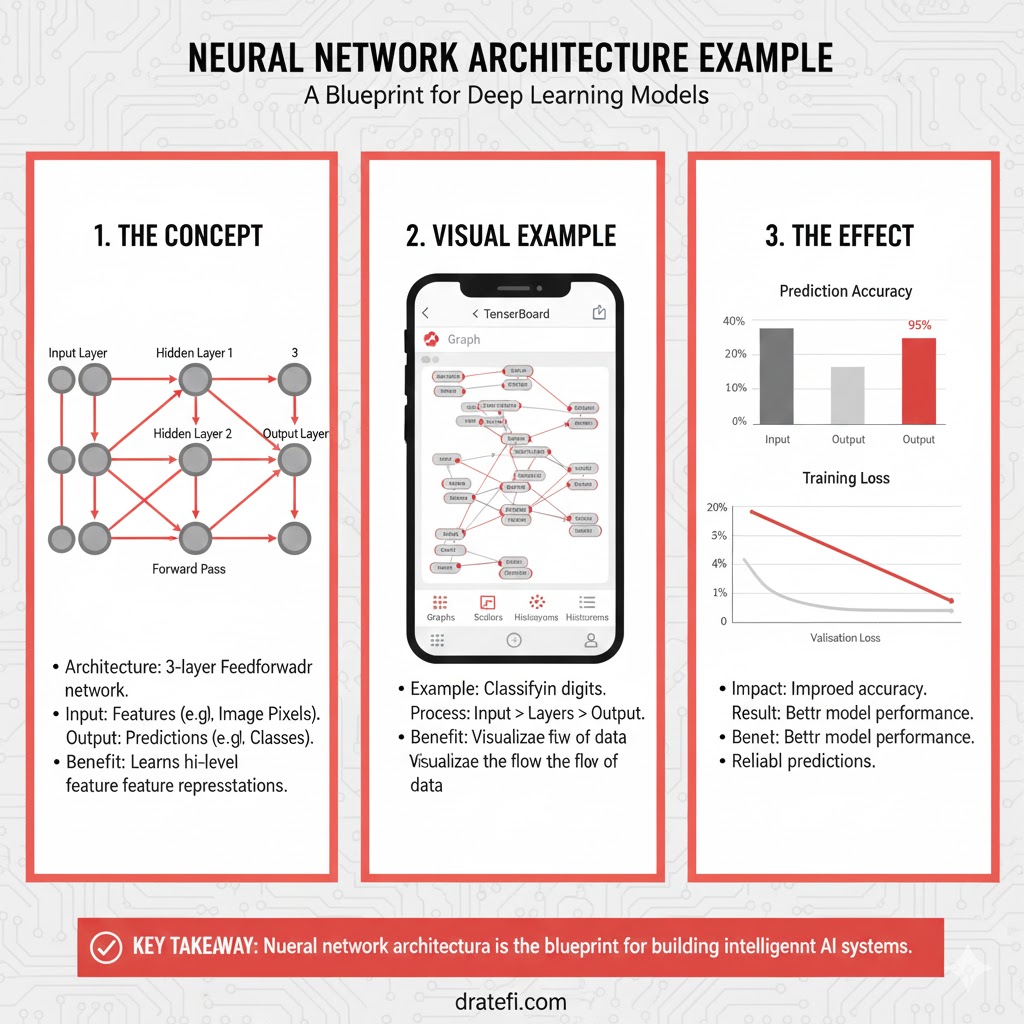
این شبکه مانند یک سیستم فیلتر هوشمند عمل میکند که در هر مرحله، دادهها را پختهتر میکند:
- لایه ورودی (۴-L1 نورون): این لایه فقط نقش «دریافتکننده» را دارد. دادههای آرش یا سارا (تعداد خرید، امتیاز و…) را میگیرد و بدون تغییر به لایه بعد میفرستد.
- لایه پنهان اول ( ۵- L2 نورون):
این لایه شروع به ترکیب ویژگیها میکند. مثلاً میسنجد که «آیا کسی که خرید کمی دارد و امتیاز پایینی داده، خطرناکتر است یا کسی که خرید زیاد دارد ولی دیر به دیر سر میزند؟» (استخراج ویژگیهای اولیه).
- لایه پنهان دوم (۳- L3 نورون):
این لایه ویژگیهای لایه قبلی را فشردهتر و عمیقتر بررسی میکند. در اینجا مدل سعی میکند «الگوهای رفتاری» پیچیده را پیدا کند که از چشم انسان پنهان است.
- لایه خروجی (۲ – L4 نورون خروجی Q1 و Q2):
در نهایت، شبکه دو خروجی به ما میدهد:
- Q1: احتمال ماندن مشتری.
- Q2: احتمال رفتن (ریزش) مشتری.
هر کدام که عدد بزرگتری داشته باشد، پیشبینی نهایی مدل است.
۴. فرآیند انتشار رو به جلو (Forward Propagation)
وقتی دادههای آرش وارد میشود:
- وزندهی: هر ویژگی آرش در یک عدد (وزن) ضرب میشود. مثلاً اگر «آخرین بازدید» برای ما خیلی مهم باشد، وزن بالایی به آن اختصاص مییابد.
- ترکیب: در هر نورون لایه پنهان، این مقادیر با هم جمع شده و با یک «بایاس» (عدد ثابت برای انعطاف مدل) ترکیب میشوند.
- فعالسازی: نتیجه از یک تابع (مثل ReLU) عبور میکند تا شبکه بفهمد این سیگنال چقدر اهمیت دارد و باید به لایه بعد منتقل شود یا خیر.
- نتیجه: در نهایت Q2 عدد بالایی (مثلاً ۰.۸۵) را نشان میدهد که یعنی آرش به احتمال ۸۵٪ دیگر از ما خرید نخواهد کرد.
شبکه عصبی تماممتصل (FNN) و محاسبات آن
در ادامه تکمیل مطالعه موردی قبلی، بیایید نگاهی دقیقتر به ساختار ریاضی و گامهای اجرایی شبکهای بیندازیم که برای مشتریان ایرانی (مانند آرش و سارا) طراحی کردیم. این مدل که به آن شبکه عصبی پیشخور (Feedforward) یا متراکم (Dense) نیز گفته میشود، به این دلیل «تماممتصل» نامیده میشود که هر نورون به تمام خروجیهای لایه قبل متصل است.
۱. نامگذاری و ساختار لایهها
برای درک بهتر جریان داده، نورونهای لایههای پنهان را نامگذاری میکنیم:
- لایه پنهان اول(L2): شامل ۵ نورون که آنها را N1 تا N5 مینامیم.
- لایه پنهان دوم(L3) : شامل ۳ نورون به نامهای N6، N7 و N8 .
- لایه خروجی(L4): در مسائل طبقهبندی (مانند ریزش مشتری)، خروجی میتواند یک گره واحد (برای احتمال بله/خیر) یا چند گره (یکی برای هر دسته) داشته باشد.
۲. معادله ریاضی هر نورون
هر نورون در این شبکه، یک ترکیب خطی از ورودیها، وزنها و یک مقدار ثابت به نام بایاس را محاسبه میکند. فرمول ریاضی که در هر گره اجرا میشود به صورت زیر است:
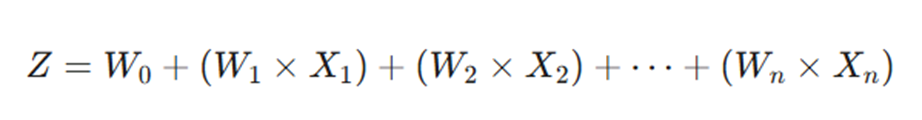
در این معادله:
- Z: خروجی خام نورون قبل از اعمال تابع فعالسازی است.
- Xها: متغیرهای ورودی (مثل سابقه خرید یا سن مشتری) هستند.
- Wها (وزنها): ضریب اهمیت هر ورودی را نشان میدهند.
- W0 (بایاس): همان عرض از مبدأ یا مقدار ثابتی است که به مدل انعطافپذیری میدهد.
۳. سه گام اصلی در اجرای شبکه عصبی
برای اینکه مدل ما بتواند وضعیت مشتریانی مثل آرش را پیشبینی کند، سه مرحله زیر را طی میکند:
گام اول: انتشار رو به جلو (Forward Propagation)
ما متغیرهای ورودی را میگیریم و با استفاده از معادله خطی فوق، خروجی یا همان مقدار پیشبینی شده(Y-pred) را محاسبه میکنیم. این دادهها از ورودی شروع شده و پس از عبور از لایههای پنهان، به لایه خروجی میرسند.
گام دوم: محاسبه تابع زیان (Loss Function)
در این مرحله، میزان خطا یا انحراف پیشبینی مدل از واقعیت محاسبه میشود. برای مثال، اگر مدل پیشبینی کند آرش میماند (Y-pred=0) اما او واقعاً ترکمان کند (Y actual=1)، این اختلاف به عنوان خطا در نظر گرفته میشود.
گام سوم: کمینهسازی خطا (Optimization)
هدف نهایی، کاهش این خطا تا حد ممکن است. شبکه با بازگشت به عقب و اصلاح وزنها (W)، سعی میکند در دفعات بعدی پیشبینی دقیقتری ارائه دهد
نحوه محاسبه خروجی یک شبکه عصبی چگونه است؟
در این بخش، ابتدا یاد میگیریم که خروجی یک شبکه عصبی چگونه محاسبه میشود و سپس روشهایی را بررسی میکنیم که به همگرا شدن مدل به سمت راه حل بهینه (حداقل کردن میزان خطا) کمک میکنند.
جریان اطلاعات و تولید خودکار ویژگیها
لایه خروجی اطلاعات را از لایه پنهان سوم (L3) دریافت میکند؛ این لایه به لایه پنهان دوم متصل است و در نهایت همه آنها به متغیرهای ورودی وصل میشوند. لایههای پنهان به صورت خودکار ویژگیها را ایجاد میکنند و نیازی به استخراج دستی آنها نیست. همین «تولید خودکار ویژگیها» است که یادگیری عمیق را از یادگیری ماشین سنتی متمایز میکند.
برای محاسبه خروجی نهایی، باید خروجی تمام گرهها (نورونها) در لایههای قبلی را محاسبه کنیم. از نظر ریاضی، هر نورون در لایههای پنهان و خروجی معادله مخصوص به خود را دارد.
معادلات ریاضی لایهها
با توجه به معماری شبکه ما (۴ ورودی، دو لایه پنهان با ۵ و ۳ نورون، و ۲ خروجی)، معادلات به شرح زیر است:
۱. گرههای لایه پنهان دوم (L2) که به متغیرهای ورودی (X) وابسته هستند:
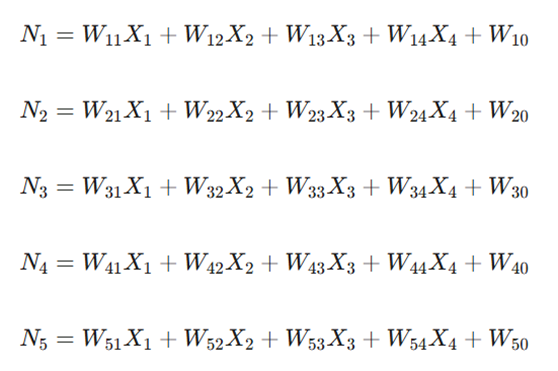
۲. گرههای لایه پنهان سوم (L3) که از نورونهای لایه قبلی (L2) مشتق میشوند:
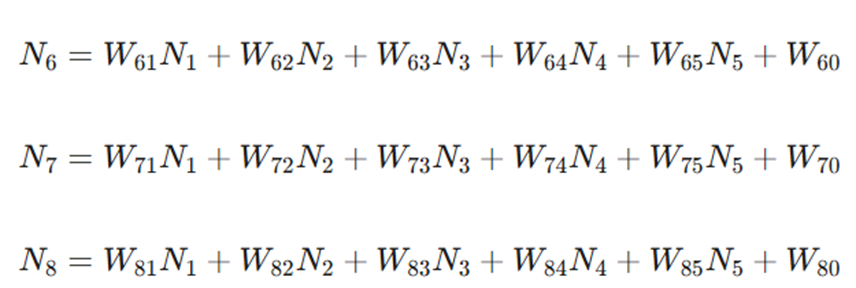
۳. گرههای لایه خروجی که از لایه پنهان L3 تغذیه میشوند:
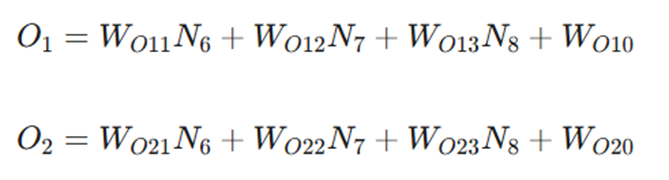
برآورد تعداد وزنها (پارامترها)
چگونه بفهمیم برای رسیدن به خروجی به چند وزن (یا همان ضرایب بتا) نیاز داریم؟ در معماری 4و5و3و2، تعداد کل وزنها ۵۱ عدد است. اما در مدلهای واقعی، تعداد ورودیها بسیار بیشتر است.
فرمول کلی برای شمارش وزنهای هر لایه:
(تعداد نورونهای لایه قبلی + ۱ عدد برای بایاس) × تعداد نورونهای لایه فعلی

بهینهسازی و اصلاح وزنها
ما چگونه این وزنها را محاسبه میکنیم؟
- مقداردهی اولیه: در اولین تکرار، مقادیر تصادفی بین ۰ و ۱ به وزنها اختصاص میدهیم.
- محاسبه خطا: خطا نشان میدهد مدل چقدر از مقادیر واقعی فاصله دارد.
- بهروزرسانی (اصلاح وزنها): برای بهبود پیشبینی، وزنها را مدام تغییر میدهیم تا میزان «زیان» یا خطا به حداقل برسد.
این تنظیم وزنها از دو طریق انجام میشود: انتشار رو به جلو (Forward Propagation) برای محاسبه خروجی و انتشار رو به عقب (Backward Propagation) برای اصلاح خطا و بهینهسازی پارامترها.
فشردهسازی شبکه عصبی (Squashing) و توابع فعالسازی
گام بعدی در نردبان محاسبات خروجی، اعمال یک «تغییر شکل» یا تبدیل (Transformation) روی این معادلات خطی است. از آنجایی که ما با یک مسئله طبقهبندی سر و کار داریم، سؤال اینجاست که یک معادله خطی ساده چطور میتواند خروجی را به دستههای مختلف تقسیم کند؟
تبدیل خطی به غیرخطی
در یک مسئله طبقهبندی دوتایی (مانند ریزش مشتری)، ما به تابع Sigmoid نیاز داریم تا معادله خطی را به یک معادله غیرخطی تبدیل کند. این فرآیند در شبکه عصبی به عنوان تابع فعالسازی (Activation Function) یا تابع فشردهسازی (Squashing) شناخته میشود.
دلیل اهمیت این تبدیل این است که بسیاری از مسائل دنیای واقعی و چالشهای تجاری را نمیتوان صرفاً با روابط خطی (مستقیم) حل کرد.
محاسبات ریاضی در هر گره
برای یک گره خاص مانند N1، ابتدا ترکیب خطی محاسبه میشود:
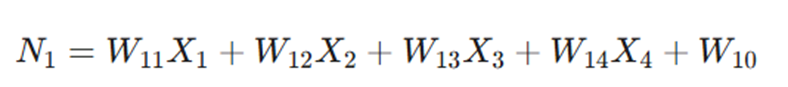
سپس با اعمال تابع سیگموید، خروجی نهایی آن نورون (h1) به دست میآید:
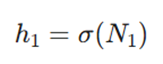
فرمول دقیق ریاضی آن به این صورت است:
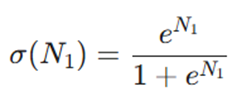
این تغییر روی تمام گرههای لایههای پنهان و لایههای خروجی اعمال میشود. خروجی واقعی هر نورون، در حقیقت نتیجهی همین تابع فعالسازی است.
پایان گام اول: انتشار رو به جلو
تا این لحظه، ما فقط گام اول شبکه عصبی را به پایان رساندهایم: یعنی دریافت متغیرهای ورودی و رسیدن به خروجی. پس از این مرحله، باید میزان خطا (Error Term) را محاسبه کنیم.
نکته مهم: تمام این محاسبات پیچیده تا الان فقط برای یک ردیف (رکورد) از دادهها انجام شده است! این چرخه باید برای تمام رکوردهای موجود در پایگاه داده تکرار شود.
نیاز به نگرانی نیست؛ شما مجبور نیستید این کار را به صورت دستی انجام دهید. اینها فرآیندهایی هستند که شبکه در پسزمینه خود انجام میدهد تا ما منطق کارکرد آن را درک کنیم.
حرکت در شبکه
در یک شبکه عصبی، ما میتوانیم از چپ به راست و همچنین از راست به چپ حرکت کنیم:
- انتشار رو به جلو (Forward Propagation): حرکت از ورودی به خروجی برای پیشبینی.
- انتشار رو به عقب (Backward Propagation): فرآیند حرکت از راست به چپ (از خروجی به سمت ورودی) برای تنظیم و اصلاح وزنها که در بخشهای بعدی به آن خواهیم پرداخت.
انتشار رو به جلو (Forward Propagation)
فرآیند حرکت از چپ به راست، یعنی از لایهی ورودی به سمت لایهی خروجی، انتشار رو به جلو نامیده میشود. ما در این مسیر حرکت میکنیم تا با استفاده از معادلات ریاضی، پیشبینیها را انجام داده و در نهایت وزنها را برای رسیدن به کمترین میزان خطا (Loss Function) اصلاح کنیم.
در مسئلهی طبقهبندی دوتایی ما، مجموعهداده شامل ویژگیهای زیر است:
- متغیر ورودی (X): یک ماتریس 4×8 که شامل ۴ متغیر ورودی (ویژگی) و ۸ ردیف داده (نمونه) است.
- متغیر هدف (Y): یک ماتریس 2×8 که دارای دو ستون برای کلاسهای ۱ و ۰ (مانند ریزش یا ماندگاری مشتری) در ۸ ردیف است.
پیشپردازش و متغیرهای دستهای
همانطور که در فایل مستندات شما اشاره شده است، لایهی ورودی دادههای خام را دریافت میکند. اگر دادهها دارای متغیرهای دستهای (مانند شهر یا جنسیت) باشند، باید آنها را به متغیرهای عددی (Dummy Variables) تبدیل کنیم. این کار معمولاً از طریق کُدگذاری تک-فعال (One-Hot Encoding) انجام میشود تا برای لایههای پنهان قابل پردازش باشند.
مراحل ریاضی در یک نگاه:
- ورود داده: ویژگیها به نورونهای لایهی ورودی تزریق میشوند.
- ترکیب خطی: در لایههای پنهان (مانند لایه Dense)، مقادیر در وزنها ضرب شده و با بایاس جمع میشوند (Z=WX+b).
- فعالسازی: نتیجه از یک تابع غیرخطی (مانند Sigmoid برای خروجی) عبور میکند تا احتمال نهایی محاسبه شود.
| جنسیت | سن | منطقه جغرافیایی | سابقه (سال) | وضعیت ریزش (Target) |
| مرد | ۳۹ | تهران | ۴ | ۱ (بله) |
| زن | ۴۰ | شیراز | ۶ | ۰ (خیر) |
| مرد | ۲۴ | تهران | ۳ | ۱ (بله) |
| زن | ۳۷ | تهران | ۱ | ۰ (خیر) |
| زن | ۳۴ | شیراز | ۵ | ۰ (خیر) |
| مرد | ۴۴ | شیراز | ۲ | ۰ (خیر) |
| زن | ۵۰ | تهران | ۸ | ۰ (خیر) |
| مرد | ۲۲ | شیراز | ۴ | ۱ (بله) |
براساس مستندات و معماری مورد بحث، فرآیند رسیدن به خروجی نهایی از طریق عملیات ریاضی بر روی ماتریسها انجام میشود. در اینجا نحوه محاسبه لایه به لایه را با جزئیات بررسی میکنیم:
فرآیند ضرب ماتریسی در انتشار رو به جلو (Forward Propagation)
در یک شبکه عصبی، ما با ضرب ماتریسی بین متغیرهای ورودی و وزنهای هر لایه به خروجی دست مییابیم. تعداد لایههای پنهان و نورونهای هر لایه، ابرپارامترهایی (Hyperparameters) هستند که توسط کاربر تعریف میشوند.

۱. لایه ورودی به لایه پنهان اول (L1 به L2)
ما با یک ماتریس ورودی 4 ✕ 8 شروع میکنیم (۴ ویژگی برای ۸ رکورد). این ماتریس در ماتریس وزنهای بین لایه اول و دوم ضرب میشود.
- فرمول: ماتریس ورودی (4 ✕ 8) ✕ماتریس وزنها ( 5 ✕ 5 با احتساب بایاس) منجر به تشکیل مقادیر لایه L2 میشود.
۲. حرکت بین لایههای پنهان (L2 به L3)
خروجی حاصل از مرحله قبل، اکنون به عنوان ورودی برای لایه بعدی عمل میکند. ما این ضربهای ماتریسی را در هر لایه تکرار میکنیم.
- فرمول: ماتریس حاصل از L2 در ماتریس وزنهای لایه L3 ( 3 ✕ 6 با احتساب بایاس) ضرب میشود تا مقادیر لایه L3 به دست آید.
۳. رسیدن به خروجی نهایی (L3 به L4)
این فرآیند تا رسیدن به لایه خروجی نهایی ادامه مییابد. در مثال ما، هدف رسیدن به یک ماتریس خروجی 2 ✕ 8 است (احتمال ۲ کلاس برای ۸ رکورد).
- فرمول نهایی: ضرب ماتریس لایه L3 در وزنهای لایه خروجی ( 4 ✕ 2 با احتساب بایاس) منجر به تولید پیشبینیهای نهایی میشود.
خلاصه وزنها در معماری[4, 5, 3, 2]
طبق محاسبات انجام شده در فایل شما، تعداد وزنها برای تخمین خروجی به شرح زیر است:
- لایه پنهان L2: دارای ۲۵ وزن.
- لایه پنهان L3: دارای ۱۸ وزن.
- لایه خروجی: دارای ۸ وزن.
- مجموع کل وزنها: ۵۱ پارامتر که باید در طول آموزش بهینه شوند.
نمودار محاسباتی جریان داده (Computational Flow)
در هر مرحله، ابتدا یک ترکیب خطی (Z) محاسبه شده و سپس توسط یک تابع فعالسازی (h) غیرخطی میشود.
۱. محاسبات لایه پنهان اول (از ورودی به L2):
- ورودی(X): ماتریس 4 ✕ 8
- ترکیب خطی اول:
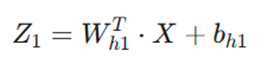
خروجی: ماتریس (5 ✕ 8)
- خروجی فعالشده:
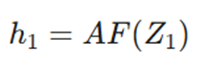
- خروجی: ماتریس (5 ✕ 8)
نکته: W_{h1} ماتریس وزنهای 4 ✕ 5 است.
۲. محاسبات لایه پنهان دوم (از L2 به L3):
- ترکیب خطی دوم:
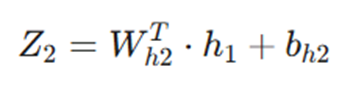
خروجی: ماتریس (3 ✕ 8)
- خروجی فعالشده:
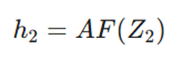
- خروجی: ماتریس (3 ✕ 8)
نکته: W_{h2} ماتریس وزنهای 5 ✕ 3 است.
۳. محاسبات لایه خروجی (از L3 به خروجی نهایی):
- ترکیب خطی نهایی:
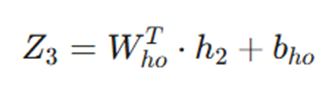
خروجی: ماتریس (2 ✕ 8)
- پیشبینی نهایی (O):
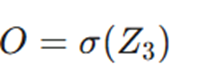
خروجی: ماتریس 2 ✕ 8))
نکته: W_{ho} ماتریس وزنهای 3 ✕ 2 است و از تابع Sigmoid (σ) برای طبقهبندی استفاده شده است.
بر اساس مستندات ارائه شده و دستنوشتهی فنی شما، فرآیند انتشار رو به جلو (Forward Propagation) از طریق ضرب ماتریسی برای کل مجموعهداده (۸ رکورد) به شرح زیر است:
گامهای محاسباتی ضرب ماتریسی در انتشار رو به جلو
در شبکه عصبی، محاسبات برای تمام مشاهدات به صورت همزمان از طریق جبر خطی انجام میشود. فرآیند ضرب ماتریسی برای لایهی اول به این صورت است:
۱. تجزیه ماتریس وزن (W_{h1})
همانطور که اشاره کردید، برای سادهسازی محاسبات، ماتریس وزن لایهی اول (W_{h1}) که در ابتدا 5 ✕ 5 در نظر گرفته شده بود، به دو بخش تقسیم میشود:
- ماتریس ضرایب بتا (Weights): دارای ابعاد 4 ✕ 5 (۴ متغیر ورودی در لایه L1 و ۵ نورون در لایه L2).
- بردار بایاس: مقادیر ثابتی که به هر نورون اضافه میشود.
۲. عملیات ضرب ماتریسی (Matrix Multiplication)
برای به دست آوردن خروجی لایهی پنهان اول (Z_1) برای تمام ۸ رکورد، عملیات زیر انجام میشود:
- ورودی (X): ماتریسی با ابعاد 4 ✕ 8 (۴ ویژگی برای ۸ مشتری ایرانی مانند آرش، سارا و…).
- وزنها (W^T): ماتریس ترانهاده وزنها با ابعاد 5 ✕ 4 .
- فرمول:
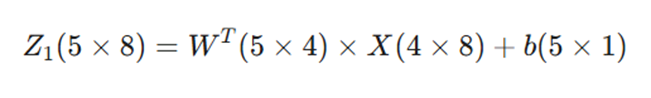
تشریح جریان داده در معماری [2,3,5,4]
این فرآیند ضرب ماتریسی در تمام لایهها تکرار میشود تا به خروجی نهایی برسیم:
- لایه L1 به: L2:ضرب ماتریس ورودی 4 ✕ 8 در وزنهای لایه اول، خروجی 5 ✕ 8 را تولید میکند.
- لایه L2 به: L3:خروجی لایه قبل (پس از اعمال تابع فعالسازی) در ماتریس وزنهای بعدی ضرب شده و خروجی 3 ✕ 8 ایجاد میشود.
- لایه L3 به خروجی: در نهایت با ضرب در آخرین ماتریس وزن، به ماتریس خروجی نهایی با ابعاد 2 ✕ 8 میرسیم.
نکته نهایی: این ماتریس 2 ✕ 8 نشاندهنده احتمالات پیشبینی شده برای هر ۸ مشتری است (مثلاً ستون اول احتمال ماندن و ستون دوم احتمال ریزش هر مشتری).
نمایش ماتریس ها
ماتریس ورودی،
این ماتریس شامل دادههای عددی ۸ مشتری است که جایگزین مقادیر متنی (مثل جنسیت و شهر) شدهاند:
| ویژگی / رکورد | مشتری ۱ (آرش) | مشتری ۲ (سارا) | مشتری ۳ (امیر) | مشتری ۴ (مریم) | مشتری ۵ | مشتری ۶ | مشتری ۷ | مشتری ۸ |
| جنسیت (مرد=۱) | ۱ | ۰ | ۱ | ۰ | ۰ | ۱ | ۰ | ۱ |
| سن | ۳۹ | ۴۰ | ۲۴ | ۳۷ | ۳۴ | ۴۴ | ۵۰ | ۲۲ |
| جغرافیا (تهران=۱) | ۱ | ۰ | ۱ | ۱ | ۰ | ۰ | ۱ | ۰ |
| سابقه (سال) | ۴ | ۶ | ۳ | ۱ | ۵ | ۲ | ۸ | ۴ |
| وضعیت واقعی (Churn) | ۱ | ۰ | ۱ | ۰ | ۰ | ۰ | ۰ | ۱ |
ماتریس وزنها، W_{h1} با مقادیر فرضی(Dummy)
این ماتریس همان «وزنهایی» است که در تکرار اول به صورت تصادفی بین ۰ و ۱ انتخاب شدهاند تا در دادههای ورودی ضرب شوند:
| وزنها | نورون ۱ | نورون ۲ | نورون ۳ | نورون ۴ | نورون ۵ |
| وزن ۱ | ۰.۹ | ۰.۷ | ۰.۲ | ۱ | ۰.۳ |
| وزن ۲ | ۰.۱ | ۱ | ۰.۵ | ۱ | ۰.۱ |
| وزن ۳ | ۰.۲ | ۰.۳ | ۰.۸ | ۰.۴ | ۰.۲ |
| وزن ۴ | ۱ | ۰.۴ | ۰.۱ | ۰.۶ | ۱ |
| بایاس (W0) | ۰.۵ | ۰.۶ | ۱ | ۰.۷ | ۰.۸ |
تحلیل کوتاه:
این جداول زیربنای محاسباتی هستند که با فرمول Z_1 = W^T . X + b نشان داده شده بود. در واقع، هر ستون از ماتریس مشتریان در ستونهای ماتریس وزنها ضرب میشود تا اولین حدس شبکه درباره رفتار مشتری شکل بگیرد.
اکنون به مرحله نهایی محاسبات ماتریسی در فرآیند انتشار رو به جلو (Forward Propagation) رسیدیم. بر اساس توضیحات ، برای اینکه بتوانیم پیشبینی را برای هر ۸ مشتری (از جمله آرش و سارا) به صورت همزمان انجام دهیم، از جبر خطی و ضرب ماتریسی استفاده میکنیم.
حل چالش ابعاد با استفاده از ترانهاده (Transpose)
برای ضرب دو ماتریس، تعداد ستونهای ماتریس اول باید با تعداد سطرهای ماتریس دوم برابر باشد.
- مشکل: ماتریس ورودی ما (X) دارای ۸ ستون است، اما ماتریس وزنها (W_{h1}) دارای ۴ سطر است.
- راهحل: ماتریس وزنها را ترانهاده میکنیم (W_{h1}^T) تا ابعاد آن از 4 ✕ 5 به 5 ✕ 4 تغییر کند.
محاسبات لایه به لایه (از ورودی تا خروجی)
گام اول: محاسبه لایه پنهان اول (L2)
با ضرب ماتریس ترانهاده وزنها در ورودی و اضافه کردن بایاس، خروجی خام (Z_1) به دست میآید:
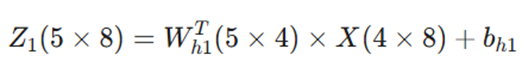
سپس با اعمال تابع فعالسازی، خروجی نهایی این لایه (h_1) با همان ابعاد 5 ✕ 8 تولید میشود.
گام دوم: محاسبه لایه پنهان دوم (L3)
در این مرحله، ورودی ما دیگر X نیست، بلکه h_1 است که از لایه قبل به دست آمده است:
- ماتریس وزن جدید (W_{h2}^T) دارای ابعاد 3 ✕ 5 است.
- فرمول: Z_2 (3 ✕ 8) = W_{h2}^T (3 ✕ 5) ✕ h_1 (5 ✕ 8) + b_{h2} .
خروجی نهایی این لایه (h_2) ابعاد 3 ✕ 8 خواهد داشت.
گام سوم: محاسبه لایه خروجی نهایی (L4)
اکنون ورودی ما h_2 است:
- ماتریس وزن خروجی (W_{h0}^T) دارای ابعاد 2 ✕ 3 است.
- فرمول: Z_3 (2 ✕ 8) = W_{h0}^T (2 ✕ 3) ✕ h_2 (3 ✕ 8) + b_{h0} .
- فشردهسازی نهایی: در اینجا از تابع Sigmoid استفاده میکنیم تا خروجی نهایی (O) با ابعاد 2 ✕ 8 به دست آید. این ماتریس شامل احتمالات پیشبینی شده برای هر ۸ رکورد است.
نتیجهگیری و گام بعدی
تخمین صحیح تعداد نورونها برای جلوگیری از بیشبرازش (Overfitting) یا کمبرازش (Underfitting) حیاتی است. فرآیند انتشار رو به جلو به شبکه اجازه میدهد تا پیشبینیها را انجام دهد. پس از این مرحله، ما میزان خطا را محاسبه میکنیم.
نکته کلیدی: روش ارجح برای اصلاح وزنها و کاهش این خطا، انتشار رو به عقب (Backward Propagation) است که در بخشهای بعدی به آن خواهیم پرداخت.
جمع بندی
انتشار رو به جلو (Forward Propagation) فرآیندی است که طی آن دادههای ورودی با عبور از لایههای شبکه عصبی، بهصورت مرحلهبهمرحله به خروجی نهایی تبدیل میشوند. در این مسیر، وزنها، بایاسها و توابع فعالسازی نقش کلیدی در شکلدهی نمایشهای میانی و تولید پیشبینی ایفا میکنند. درک این فرآیند، پایهی فهم نحوه یادگیری شبکههای عصبی و عملکرد آنها در مسائل واقعی است.
در این مقاله دیدیم که انتخاب تعداد نورونها و نحوه سازماندهی لایهها، تصمیمی صرفاً سلیقهای نیست؛ بلکه مستقیماً بر تعادل میان بیشبرازش و کمبرازش، توان تعمیمپذیری مدل و هزینه محاسباتی تأثیر میگذارد. مثالهای عددی و ماتریسی نشان دادند که چگونه تغییر در ساختار شبکه، مسیر محاسبات و خروجی نهایی را دگرگون میکند.
در نهایت، تسلط بر انتشار رو به جلو به شما کمک میکند شبکههای عصبی را نه بهعنوان یک جعبه سیاه، بلکه بهعنوان سیستمی شفاف و قابل تحلیل ببینید. این درک، پیشنیاز ورود به مبحث پسانتشار (Backpropagation) و بهینهسازی وزنهاست؛ جایی که شبکه از خطاهای خود یاد میگیرد و فرآیند آموزش بهصورت واقعی آغاز میشود.



