
مقدمه
اساس تکامل انسان، یادگیری از اشتباهات گذشته است. اما سؤالی که مطرح میشود این است: آیا ماشینها هم میتوانند از خطاهایشان درس بگیرند؟ جواب مثبت است! در دنیای شبکههای عصبی و هوش مصنوعی، مدلها همواره در تلاشاند تا بهترین پیشبینیها را ارائه دهند. اما هیچ بهبودی حاصل نمیشود مگر اینکه راهی برای مقایسه خروجی فعلی با “اشتباهات قبلی” وجود داشته باشد.
اینجاست که در فرآیند انتشار رو به عقب (Backpropagation)، مفهومی به نام تابع زیان (Loss Function) وارد صحنه میشود.
تعریف
تابع زیان که با نامهای تابع خطا (Error Function) یا تابع هزینه (Cost Function) نیز شناخته میشود، در واقع معیاری برای سنجش خطاهای ماشین در طول فرآیند آموزش است. ماشین با استفاده از یک بهینهساز (Optimizer) و تنظیم مداوم وزنها (Weights)، تلاش میکند این زیان را به حداقل برساند تا به دقیقترین نتایج دست یابد.
پیادهسازی در TensorFlow
اگر از کتابخانه محبوب TensorFlow استفاده میکنید، اکثر توابع زیان را میتوانید در مسیر زیر پیدا کنید: tensorflow.keras.losses
توابع زیان احتمالات (Probabilistic Loss Functions)
یکی از مهمترین دستههای توابع زیان، توابع مبتنی بر احتمالات هستند. در ادامه با آنها آشنا میشویم:
۱. زیان آنتروپی متقاطع دوتایی (Binary Cross-Entropy Loss)
۲. زیان آنتروپی متقاطع دستهای (Categorical Cross-Entropy)
۳. زیان آنتروپی متقاطع دستهای پراکنده (Sparse Categorical Cross-Entropy)
۴. زیان پواسون (Poisson Loss)
۵. زیان واگرایی کولبک-لایبلر (Kullback-Leibler Divergence)
۱. زیان آنتروپی متقاطع دوتایی (Binary Cross-Entropy Loss)
این زیان که اغلب با نام Log Loss نیز شناخته میشود، ابزاری برای سنجش عملکرد مدلهای دستهبندی است که خروجی آنها یک عدد بین ۰ و ۱ (احتمال) میباشد. این تابع تفاوت بین توزیع احتمالات پیشبینی شده توسط مدل و توزیع واقعی برچسبها را محاسبه میکند. به زبان ساده، BCE مدل را بر اساس میزان دوری یا نزدیکیِ “احتمالِ پیشبینی شده” به “برچسب واقعی” جریمه میکند.
مزایا:
- جریمه سنگین برای اطمینان اشتباه: اگر مدل با اطمینان بالا یک خروجی غلط بدهد، این تابع با مقدار Loss بسیار بزرگی آن را جریمه میکند که باعث اصلاح سریع وزنها میشود.
- سازگاری با توابع فعالساز: این تابع زیان به خوبی با تابع فعالساز Sigmoid ترکیب میشود و شیبهای مناسبی را برای الگوریتم گرادیان کاهشی فراهم میکند.
- دقت در احتمالات: به جای فقط “درست یا غلط” دیدن خروجی، به “میزان اطمینان” مدل اهمیت میدهد که منجر به آموزش دقیقتر میشود.
معایب:
- حساسیت به دادههای پرت: به دلیل ماهیت لگاریتمی، پیشبینیهای بسیار غلط (نزدیک به ۰ برای برچسب ۱) میتوانند مقدار زیان را به سمت بینهایت ببرند و آموزش را ناپایدار کنند.
- فقط برای دو کلاس: این نسخه از آنتروپی متقاطع فقط برای مسائل “صفر و یکی” طراحی شده و برای مسائل چندکلاسه باید از نسخههای دیگر استفاده کرد.
کاربردها و مثال
- کاربرد اصلی: هر مسألهای که در آن فقط دو انتخاب وجود دارد (Binary Classification).
- مثالهای دنیای واقعی:
- پزشکی: تشخیص اینکه یک تومور سرطانی است (۱) یا خوشخیم (۰).
- امنیت: تشخیص اینکه یک تراکنش بانکی مشکوک است یا عادی.
- بینایی ماشین: تشخیص سگ در برابر گربه در یک تصویر
مثال عملی: کدگذاری در TensorFlow
## Binary Corss Entropy Calculation
import tensorflow as tf
#input lables.
y_true = [[0.,1.],
[0.,0.]]
y_pred = [[0.5,0.4],
[0.6,0.3]]
binary_cross_entropy = tf.keras.losses.BinaryCrossentropy()
binary_cross_entropy(y_true=y_true,y_pred=y_pred).numpy()
خروجی:
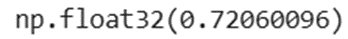
.
۲. زیان آنتروپی متقاطع دستهای (Categorical Cross-Entropy)
این تابع ابزار اصلی ما برای مسائل دستهبندی چندکلاسه (Multiclass Classification) است. زمانی که میخواهید بین چندین دسته (مثلاً گربه، سگ، فیل و اسب) تمایز قائل شوید، این تابع زیان بین برچسبهای واقعی و پیشبینیهای مدل، مقدار خطا را محاسبه میکند.
- مزیت اصلی: دقت بالا در تفکیک چندین کلاس به صورت همزمان.
- نکته فنی: در این روش، برچسبها باید به صورت کُدگذاری تک-فعال (One-Hot Encoding) باشند.
مثال پیادهسازی درTensorFlow:
import tensorflow as tf
# برچسبها به صورت One-Hot
y_true = [[0, 1, 0], [0, 0, 1]]
y_pred = [[0.05, 0.95, 0.56], [0.1, 0.4, 0.1]]
cce = tf.keras.losses.CategoricalCrossentropy()
print(f"میزان زیان: {cce(y_true, y_pred).numpy()}")
خروجی:
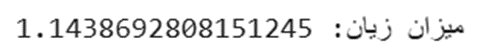
.
۳. زیان آنتروپی متقاطع دستهای پراکنده (Sparse Categorical Cross-Entropy)
این تابع عملکردی کاملاً مشابه مورد قبلی دارد و برای مسائل با دو یا چند کلاس استفاده میشود. تنها یک تفاوت کلیدی وجود دارد که کار شما را راحتتر میکند:
- تفاوت اصلی: در این تابع، برچسبهای واقعی (y_true) به جای کدگذاری تک-فعال، به صورت اعداد صحیح ارائه میشوند.
مثال پیادهسازی:
# برچسبها به صورت عدد صحیح (کلاس 1 و کلاس 2)
y_true = tf.constant([1, 2])
y_pred = tf.constant([[0.05, 0.95, 0], [0.1, 0.8, 0.1]])
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred)
print(f"میزان زیان پراکنده: {loss.numpy()}")
خروجی:
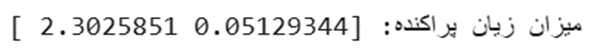
.
۴. زیان پواسون (Poisson Loss)
این زیان در واقع میانگین عناصر یک تنسور است و از فرمول ریاضی ypred – ytrue. log(ytrue) پیروی میکند.
- کاربرد: این تابع زمانی مفید است که بخواهید تعداد وقوع یک رویداد در یک بازه زمانی یا مکانی مشخص را پیشبینی کنید (مثلاً پیشبینی تعداد کلیکهای یک تبلیغ در ساعت).
مثال پیادهسازی:
y_true = [[0., 1.], [0., 0.]]
y_pred = [[1., 1.], [1., 0.]]
p = tf.keras.losses.Poisson()
print(f"زیان پواسون: {p(y_true, y_pred).numpy()}")
خروجی:

.
۵. زیان واگرایی کولبک-لایبلر (Kullback-Leibler Divergence)
این تابع که به اختصار KL Divergence نامیده میشود، برای اندازهگیری میزان تفاوت یک توزیع احتمال (P) با توزیع احتمال دوم (Q) به کار میرود . فرمول آن مجموع منفی احتمال هر رویداد ضربدر لگاریتم نسبت احتمالات است.

- کاربرد: زمانی که میخواهید یک توزیع پیچیده را با یک توزیع سادهتر تقریب بزنید (مثل مدلهای VAE یا یادگیری توزیع دادهها).
مثال پیادهسازی:
y_true = [[0, 1], [0, 0]]
y_pred = [[0.7, 0.8], [0.4, 0.8]]
kl = tf.keras.losses.KLDivergence()
print(f"میزان واگرایی KL: {kl(y_true, y_pred).numpy()}")
خروجی:
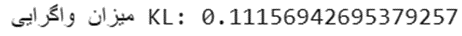
.
توابع زیان رگرسیون (Regression Loss Functions)
این توابع به ما میگویند که مدل چقدر در تخمین زدن اعداد واقعی موفق بوده است.

۶. میانگین مربعات خطا (Mean Squared Error – MSE)
تعریف: MSE نشان میدهد که خط رگرسیون چقدر به نقاط پیشبینی شده نزدیک است. این کار به سادگی با محاسبه فاصله نقاط تا خط رگرسیون و به توان دو رساندن آنها انجام میشود. به توان دو رساندن فاصلهها الزامی است تا مشکل علامت منفی (خنثی شدن خطاها) از بین برود.
- مزایا: اشتباهات بزرگ را به شدت جریمه میکند که باعث میشود مدل سعی کند خطاهای فاحش نداشته باشد.
- معایب: به شدت نسبت به دادههای پرت (Outliers) حساس است.
پیادهسازی در TensorFlow:
import tensorflow as tf
# برچسبهای واقعی و پیشبینی شده
y_true = [[10., 10.], [0., 0.]]
y_pred = [[10., 10.], [1., 0.]]
mse = tf.keras.losses.MeanSquaredError()
print(f"MSE Loss: {mse(y_true, y_pred).numpy()}")
خروجی:
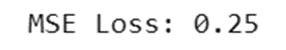
.
۷. میانگین قدر مطلق خطا (Mean Absolute Error – MAE)
تعریف: MAE به سادگی از طریق محاسبه فاصله مستقیم (قدر مطلق) هر نقطه تا خط رگرسیون به دست میآید. برخلاف MSE، در اینجا خطاها به توان دو نمیرسند.
- مزایا: نسبت به MSE در برابر دادههای پرت (Outliers) مقاومتر است.
- نکته مهم: قبل از استفاده از MAE، مطمئن شوید دادههای شما حاوی مقادیر بسیار پرت نباشند، زیرا این تابع نسبت به آنها حساسیت متفاوتی دارد.
پیادهسازی در TensorFlow:
y_true = [[10., 20.], [30., 40.]]
y_pred = [[10., 20.], [30., 0.]]
mae = tf.keras.losses.MeanAbsoluteError()
print(f"MAE Loss: {mae(y_true, y_pred).numpy()}")
خروجی:
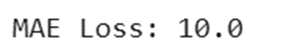
.
۸. زیان شباهت کسینوسی (Cosine Similarity Loss)
تعریف: شباهت کسینوسی معیاری برای سنجش شباهت بین دو بردار غیرصفر است. این تابع زیان، شباهت کسینوسی بین برچسبهای واقعی و پیشبینیها را محاسبه میکند. خروجی آن عددی بین ۱ و ۱ – است.

- تحلیل خروجی: عدد ۰ نشاندهنده تعامد (عدم شباهت) است و هرچه مقدار به ۱ – نزدیکتر باشد، شباهت بین پیشبینی و واقعیت بیشتر است.
پیادهسازی در TensorFlow:
y_true = [[10., 20.], [30., 40.]]
y_pred = [[10., 20.], [30., 0.]]
cosine_loss = tf.keras.losses.CosineSimilarity(axis=1)
print(f"Cosine Similarity Loss: {cosine_loss(y_true, y_pred).numpy()}")
خروجی:
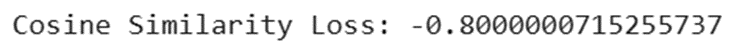
.
۹. زیان هیوبر (Huber Loss)
تعریف: این تابع یک ترکیب هوشمندانه است؛ برای خطاهای کوچک به صورت درجه دو (Quadratic) و برای خطاهای بزرگ به صورت خطی (Linear) عمل میکند. این ویژگی باعث میشود هیوبر مزایای MSE و MAE را همزمان داشته باشد.
فرمول ریاضی:
برای هر مقدار X (تفاوت واقعی و پیشبینی)، زیان به صورت زیر محاسبه میشود:
- اگر X| ≤ d|:
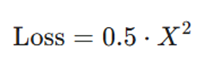
- اگر X| > d|:
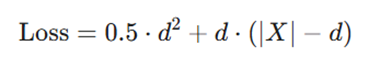
پیادهسازی در TensorFlow:
y_true = [[10., 20.], [30., 40.]]
y_pred = [[10., 20.], [30., 0.]]
hub_loss = tf.keras.losses.Huber()
print(f"Huber Loss: {hub_loss(y_true, y_pred).numpy()}")
خروجی:
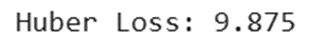
.
۱۰. زیان لگاریتم کسینوس هیپربولیک (LogCosh Loss)
تعریف: این تابع لگاریتمِ کسینوس هیپربولیکِ خطای پیشبینی را محاسبه میکندLogCosh. مشابه MSE عمل میکند اما نسبت به خطاهای بسیار بزرگِ ناشی از دادههای پرت، حساسیت کمتری دارد و هموارتر است.
پیادهسازی در TensorFlow:
y_true = [[0., 1.], [0., 0.]]
y_pred = [[1., 1.], [1., 0.]]
l = tf.keras.losses.LogCosh()
print(f"LogCosh Loss: {l(y_true, y_pred).numpy()}")
خروجی:
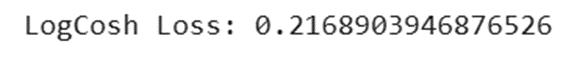
.
توابع زیان هینج (Hinge Loss Functions)
این توابع زیان بهجای تمرکز بر احتمالات (مانند Cross-Entropy)، بر روی فاصله نقاط از مرز تصمیمگیری تمرکز میکنند.
۱۱. زیان هینج (Hinge Loss)
این تابع زیان عمدتاً در مدلهایی کاربرد دارد که هدف آنها یافتن مرزی با بیشترین فاصله از دادههاست (مانند SVM). در این تابع، انتظار میرود مقادیر برچسبها ۱ یا ۱ – باشند. اگر دادههای شما به صورت صفر و یک (Binary) باشند، خودِ الگوریتم آنها را به ۱- و ۱ تبدیل میکند.
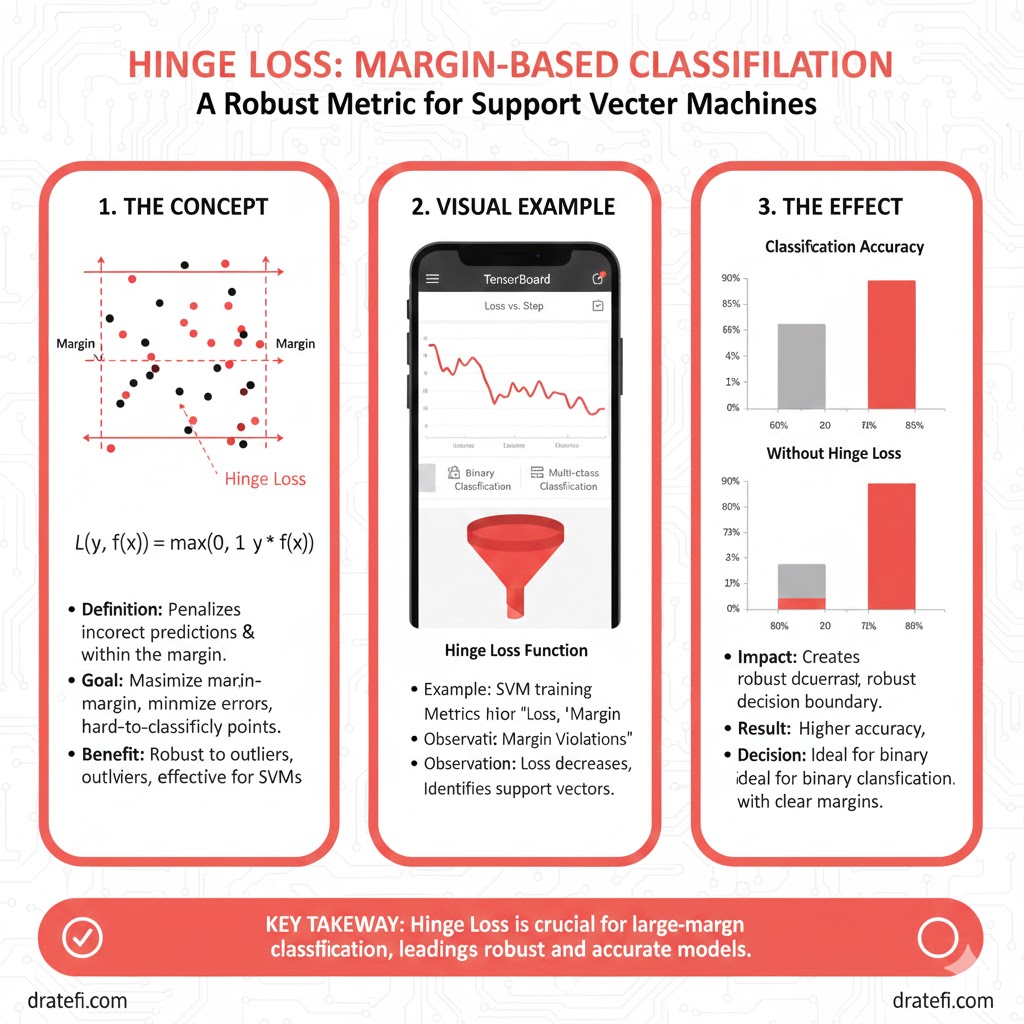
- ویژگی اصلی: این تابع زمانی مقدار صفر را برمیگرداند که دادهها نهتنها درست دستهبندی شده باشند، بلکه با حاشیه اطمینان کافی از مرز فاصله داشته باشند.
پیادهسازی در TensorFlow:
import tensorflow as tf
# برچسبهای واقعی و پیشبینی شده
y_true = [[0., 1.], [0., 0.]]
y_pred = [[0.5, 0.4], [0.4, 0.5]]
h_loss = tf.keras.losses.Hinge()
print(f"Hinge Loss: {h_loss(y_true, y_pred).numpy()}")
خروجی:
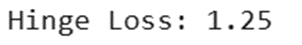
.
۱۲. زیان هینج مربعی (Squared Hinge Loss)
همانطور که از نامش پیداست، این تابع صرفاً توان دوم (مربع) تابع زیان Hinge است.
- تفاوت کلیدی: به دلیل به توان دو رسیدن، این تابع جریمه سنگینتری برای نقاطی که در سمت اشتباه مرز قرار دارند یا در محدوده حاشیه (Margin) هستند، در نظر میگیرد و سطح خطای هموارتری برای بهینهسازی ایجاد میکند.
پیادهسازی در TensorFlow:
y_true = [[0., 1.], [0., 0.]]
y_pred = [[0.5, 0.4], [0.4, 0.5]]
h_squared = tf.keras.losses.SquaredHinge()
print(f"Squared Hinge Loss: {h_squared(y_true, y_pred).numpy()}")
خروجی:
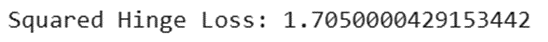
.
۱۳. زیان هینج دستهای (Categorical Hinge Loss)
این نسخه از تابع هینج برای مسائل دستهبندی چندکلاسه (Multiclass) که از استراتژی حاشیه حداکثری استفاده میکنند، طراحی شده است. این تابع میزان زیان را بین برچسبهای واقعی و پیشبینیهای چندکلاسه محاسبه میکند.
پیادهسازی در TensorFlow:
y_true = [[0., 1.], [0., 0.]]
y_pred = [[0.5, 0.4], [0.4, 0.5]]
h_categorical = tf.keras.losses.CategoricalHinge()
print(f"Categorical Hinge Loss: {h_categorical(y_true, y_pred).numpy()}")
خروجی:
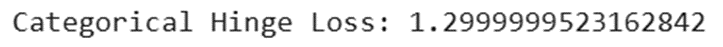
.
جمعبندی نهایی توابع زیان
با اتمام این بخش، ما تمام دستههای اصلی توابع زیان در TensorFlow را پوشش دادیم:
- توابع احتمالات: برای دستهبندی بر اساس احتمال (مثل Cross-Entropy).
- توابع رگرسیون: برای پیشبینی مقادیر عددی (مثل MSE و Huber).
- توابع هینج: برای دستهبندیهای مبتنی بر مرز و حاشیه
جدول راهنمای انتخاب تابع زیان در TensorFlow
| نوع مسئله | شرایط داده | تابع زیان پیشنهادی | دلیل انتخاب |
| رگرسیون | داده بدون نویز شدید | Mean Squared Error (MSE) | حساس به خطاهای بزرگ، همگرایی خوب |
| رگرسیون | وجود دادههای پرت (Outliers) | Mean Absolute Error (MAE) | مقاومتر در برابر دادههای غیرعادی |
| رگرسیون | ترکیب دقت و پایداری | Huber Loss | تعادل بین MSE و MAE |
| رگرسیون | داده با توزیع خاص | Log-Cosh | نرم، پایدار و مشتقپذیر |
| طبقهبندی دودویی | خروجی باینری | Binary Cross-Entropy | استاندارد برای مسائل دودویی |
| طبقهبندی چندکلاسه | برچسب One-Hot | Categorical Cross-Entropy | سازگار با Softmax |
| طبقهبندی چندکلاسه | برچسب عددی | Sparse Categorical Cross-Entropy | حافظهبهینهتر |
| مسائل شمارشی | دادههای Count | Poisson Loss | مناسب مدلسازی رخدادها |
| یادگیری توزیعی | مقایسه توزیعها | KL Divergence | سنجش فاصله بین توزیعها |
| شباهت برداری | NLP / Embedding | Cosine Similarity | تمرکز بر زاویه بردارها |
| مسائل Margin-based | SVM و مشابه | Hinge / Squared Hinge | افزایش فاصله تصمیمگیری |
جمع بندی
توابع زیان نقش محوری در فرآیند یادگیری مدلهای یادگیری ماشین و یادگیری عمیق دارند و عملاً تعیین میکنند که مدل چگونه خطاهای خود را ببیند و در چه جهتی اصلاح شود. انتخاب نادرست تابع زیان میتواند حتی دقیقترین معماریها را به نتایج ضعیف برساند، در حالی که انتخاب درست آن مسیر یادگیری را هموار و پایدار میکند.
در این مقاله دیدیم که TensorFlow مجموعهای متنوع از توابع زیان را برای انواع مسائل رگرسیون، طبقهبندی و سنجش شباهت فراهم کرده است. بررسی مزایا، محدودیتها و کاربردهای هر تابع نشان داد که تصمیمگیری درباره Loss Function نباید بر اساس عادت یا حدس انجام شود، بلکه نیازمند درک مسئله و رفتار دادههاست.
در نهایت، تابع زیان پلی میان پیشبینیهای مدل و الگوریتمهای بهینهسازی مانند گرادیان کاهشی و پسانتشار است. درک عمیق این مفهوم، شما را قادر میسازد مدلهای هوشمندتر، پایدارتر و قابلاعتمادتر طراحی کنید و از یادگیری ماشین بهصورت مهندسی و آگاهانه استفاده نمایید.



