
مقدمه
یادگیری عمیق در نگاه اول ممکن است پیچیده، ترسناک و مخصوص متخصصان حرفهای به نظر برسد. اما واقعیت این است که با ابزارها و کتابخانههای امروزی، حتی افراد مبتدی هم میتوانند در مدتزمانی کوتاه، اپلیکیشنهای جذاب و کاربردی بسازند. مسئله اصلی، دانستن این است که از کجا شروع کنیم و چه پروژهای برای سطح ما مناسب است.
در این مقاله، چند اپلیکیشن در حوزه یادگیری عمیق معرفی میکنیم که یک فرد مبتدی میتواند آنها را در چند دقیقه پیادهسازی کند. این پروژهها طوری انتخاب شدهاند که هم مفاهیم اصلی یادگیری عمیق را آموزش دهند . هم حس اعتمادبهنفس و انگیزه «من هم میتوانم بسازم» را در ابتدای مسیر ایجاد کنند.
اگر بهتازگی وارد دنیای یادگیری عمیق شدهاید و دوست دارید بهجای مطالعه تئوری، با پروژههای عملی یاد بگیرید. این مقاله دقیقاً برای شما نوشته شده است.
اپلیکیشنهایی که از APIهای آماده استفاده میکنند
API در واقع نرمافزاری است که روی یک کامپیوتر دورتر در آنسوی اینترنت اجرا میشود . شما میتوانید از سیستم محلی خود به آن دسترسی داشته باشید. برای درک سادهتر، اتصال اسپیکر بلوتوث به لپتاپ را تصور کنید. با اینکه لپتاپ خودش اسپیکر داخلی دارد، اما شما از راه دور به یک خروجی قویتر متصل میشوید.
در دنیای برنامهنویسی هم API ها دقیقاً همینطور عمل میکنند. یعنی کسانی قبلاً کارهای سخت و پیچیده را انجام دادهاند و شما فقط از نتیجه کار آنها برای حل سریع مشکل خود استفاده میکنید.
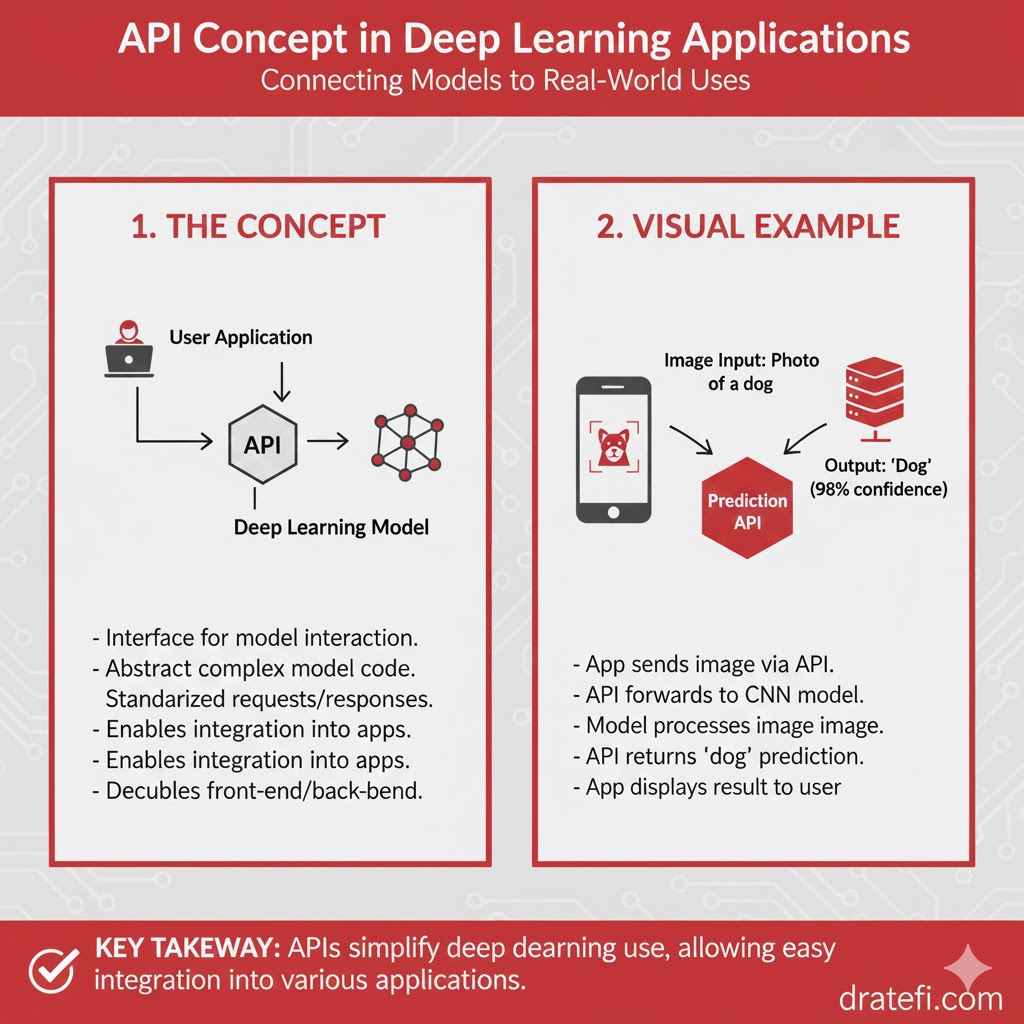
مزایا
یک اپلیکیشن یادگیری عمیق معمولی، به قدرت محاسباتی بسیار بالا (مثل کارتهای گرافیک قوی یا همان GPU) و فضای ذخیرهسازی حجیم نیاز دارد. با استفاده از API:
- سبکی سیستم شما: کامپیوتر شخصی شما زیر بار محاسبات سنگین نمیرود و پردازش در سرورهای قدرتمند انجام میشود.
- توسعه سریع: میتوانید قابلیتهای جدید و پیشرفته را به راحتی و با چند خط کد به برنامه خود اضافه کنید.
معایب
- هزینه و زمان: ساخت و نگهداری یک API شخصی میتواند پرهزینه و زمانبر باشد.
- وابستگی به اینترنت: شما کاملاً به اتصال اینترنت وابستهاید؛ اگر اینترنت قطع شود، کل سیستم از کار میافتد.
- چالشهای امنیتی: برنامه شما در بستر شبکه قرار دارد. باید لایههای امنیتی اضافهای مثل رمز عبور و محدودیت تعداد درخواست (Rate Limit) برای آن تعریف کنید.
رنگی کردن عکسها با یادگیری عمیق (Algorithmia API) 🎨
رنگی کردن خودکار تصاویر همیشه یکی از موضوعات جذاب در دنیای بینایی ماشین بوده است. اینکه بتوانید به یک عکس سیاه و سفید قدیمی، جانی تازه ببخشید، واقعاً جادویی به نظر میرسد. درست مثل یک کودک ۴ ساله که با مداد رنگیهایش غرق در رنگآمیزی کتابش میشود. ما هم میخواهیم به یک عامل هوشمند یاد بدهیم که رنگها را تصور کند!
البته که این کار بسیار دشوار است. چرا؟ چون ما انسانها هر روز با دیدن دنیای واقعی در حال آموزش دیدن هستیم. مغز ما ناخودآگاه ثبت میکند که آسمان آبی و چمن سبز است؛ اما مدلسازی این حجم از درک در یک ماشین کار سادهای نیست.
مطالعات اخیر نشان داده که اگر یک شبکه عصبی را با حجم عظیمی از دادههای مخصوص آموزش دهیم. میتوانیم مدلی بسازیم که رنگها را در یک تصویر خاکستری توهم (Hallucinate) یا بازسازی کند.

برای اینکه بتوانید با استفاده از پایتون به تصاویر سیاه و سفید قدیمی جانی تازه ببخشید، مراحل زیر را با دقت دنبال کنید.
گام اول: دریافت کلید اختصاصی (API Key)
نخستین قدم برای برقراری ارتباط بین کد شما و مغز متفکر هوش مصنوعی، دریافت مجوز عبور یا همان کلید API است:
- ثبتنام: ابتدا در وبسایت Algorithmia یک حساب کاربری بسازید.
- بخش پروفایل :پس از ورود، به قسمت Profile یا Credentials بروید.
- کپی کلید:کلید اختصاصی خود را یافته و کپی کنید؛ این کلید محرمانه را برای استفاده در کد نگه دارید.
گام دوم: نصب کتابخانه Algorithmia
برای اینکه پایتون بتواند با سرورهای مقصد صحبت کند، باید ابزار واسط را نصب کنید.
- دستور نصب: ترمینال یا Command Prompt را باز کرده و دستور زیر را اجرا کنید:
pip install algorithmiaگام سوم: آپلود تصویر در فضای ابری ☁️
مدل هوش مصنوعی برای پردازش، باید به فایل شما دسترسی داشته باشد:
- انتخاب تصویر: یک عکس سیاه و سفید باکیفیت (مثلاً یک تصویر تاریخی یا خانوادگی) آماده کنید.
- آپلود فایل: در پنل کاربری خود در سایت، به بخش Data بروید و عکس را آپلود کنید.
- کپی آدرس فایل: پس از آپلود، آدرس اختصاصی فایل (Data URI) را که با data:// شروع میشود، کپی کنید.
گام چهارم: کدنویسی حرفهای با پایتون
یک فایل با نام trial1.py بسازید و کدهای بهروزرسانی شده زیر را در آن قرار دهید:
import Algorithmia
API_KEY = "YOUR_API_KEY"
client = Algorithmia.client(API_KEY)
input_config = {
"image": "data://username/folder/image.jpg"
}
algo = client.algo("deeplearning/ColorfulImageColorization/1.1.5")
print("در حال پردازش تصویر... لطفاً شکیبا باشید.")
try:
result = algo.pipe(input_config).result
print("-" * 30)
print("عملیات با موفقیت انجام شد!")
print("خروجی:")
print(result)
except Exception as e:
print("-" * 30)
print("خطا:", e)
گام پنجم: اجرا و تماشای جادو!
حالا وقت آن است که قدرت یادگیری عمیق را مشاهده کنید:
- اجرا: در ترمینال دستور زیر را تایپ کنید:
python trial1.py- نتیجه: پس از چند ثانیه، نسخه رنگی تصویر شما به صورت خودکار در Data Folder شما در سایت ذخیره میشود.
شما توانستید با موفقیت یک تصویر بیروح خاکستری را به عکسی زنده و پر از رنگ تبدیل کنید!

ساخت یک چتبات هوشمند (Watson API) 🤖💬
واتسون (Watson)، محصول شرکت IBM، یکی از درخشانترین نمونههای عامل هوشمند در دنیای هوش مصنوعی است. این سیستم با شکست دادن رقبای انسانی در مسابقه معروف Jeopardy، قدرت خود را در درک و پاسخگویی به سوالات پیچیده به رخ جهانیان کشید.
اگرچه واتسون از مجموعهای از تکنیکهای پیشرفته استفاده میکند، اما یادگیری عمیق (Deep Learning) قلب تپنده آن است؛ بهویژه در حوزه پردازش زبان طبیعی (NLP) که به ماشین اجازه میدهد زبان انسان را درک کرده و مانند او پاسخ دهد.
- چتبات چیست؟ یک عامل هوشمند که میتواند به سوالات متداول کاربران، دقیقاً مشابه یک انسان پاسخ دهد.
- کاربرد اصلی: این ابزار یک نقطه تماس عالی و ۲۴ ساعته برای مشتریان است که بدون خستگی، پاسخهای لحظهای ارائه میدهد.

پیشنیازها و مشخصات فنی
قبل از شروع کدنویسی، مطمئن شوید که ابزارهای زیر را در اختیار دارید:
- پایتون (Python): نسخه ۳ .
- اینترنت: برای برقراری ارتباط با مغز متفکر واتسون در فضای ابری.
- حساب کاربری IBM Cloud (Bluemix): پلتفرم ابری IBM که سرویسهای هوش مصنوعی را ارائه میدهد (دارای دوره آزمایشی رایگان ۳۰ روزه).
راهنمای گامبهگام ساخت چتبات
گام ۱: دریافت مجوزهای دسترسی (Credentials)
- در سایت IBM Cloud ثبتنام کنید.
- سرویس Watson Assistant (یا Conversation) را پیدا و فعال کنید.
- در بخش Service Credentials، کلید اختصاصی (API Key) و URL سرویس را کپی کنید. اینها کلیدهای اتصال کد شما به واتسون هستند.
گام ۲: نصب ابزارهای ارتباطی در پایتون 💻
کتابخانههای مورد نیاز را با اجرای دستور زیر در ترمینال (یا یک سلول در Google Colab) نصب کنید:
pip install requests responses
pip install --upgrade watson-developer-cloud
گام سوم: ساخت فایل و اجرای کد چتبات 📝
حالا نوبت به آن رسیده که روح هوش مصنوعی را در کالبد کدهای خود بدمید! یک فایل متنی جدید بسازید، نام آن را trial.py بگذارید و کدهای زیر را در آن کپی کنید.
نکته مهم: فراموش نکنید که اطلاعات کاربری Username)، Password یا API Key) و شناسه محیط کاری (Workspace ID) خود را که در گام اول از پنل IBM گرفتید، در جاهای مشخص شده قرار دهید.
from ibm_watson import AssistantV2
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
API_KEY = "YOUR_API_KEY"
SERVICE_URL = "YOUR_SERVICE_URL"
ASSISTANT_ID = "YOUR_ASSISTANT_ID"
authenticator = IAMAuthenticator(API_KEY)
assistant = AssistantV2(
version="2023-10-01",
authenticator=authenticator
)
assistant.set_service_url(SERVICE_URL)
# 1. ساخت session
session = assistant.create_session(
assistant_id=ASSISTANT_ID
).get_result()
session_id = session["session_id"]
# 2. ارسال پیام
response = assistant.message(
assistant_id=ASSISTANT_ID,
session_id=session_id,
input={
"message_type": "text",
"text": "What's the weather like?"
}
).get_result()
# 3. استخراج جواب
print("پاسخ چتبات:")
print(response["output"]["generic"][0]["text"])
# 4. بستن session
assistant.delete_session(
assistant_id=ASSISTANT_ID,
session_id=session_id
)
گام ۴: تست نهایی و مشاهده خروجی
فایل را ذخیره کرده و با دستور python trial.py اجرا کنید. واتسون پیام شما را تحلیل کرده و پاسخی هوشمندانه برمیگرداند.
- مثال: اگر کاربر بگوید “اطراف من چه خبر است؟”، واتسون درک میکند که منظور کاربر پیدا کردن امکانات رفاهی است و رستورانها یا پمپبنزینهای نزدیک را پیشنهاد میدهد.
نتیجه: شما توانستید در عرض چند دقیقه، یک اپلیکیشن رنگیکردن تصاویر و یک چتبات هوشمند بسازید؛ شروعی عالی برای یک مسیر حرفهای در هوش مصنوعی!
خبرخوان هوشمند بر اساس احساسات (Aylien News API)
گاهی اوقات دلمان میخواهد فقط جنبههای مثبت دنیا را ببینیم. چقدر جذاب میشد اگر میتوانستیم هنگام مطالعه اخبار، تمام خبرهای منفی را فیلتر کرده و فقط روی موارد امیدبخش تمرکز کنیم؟
با کمک تکنیکهای پیشرفته پردازش زبان طبیعی(NLP) – که یادگیری عمیق یکی از ستونهای اصلی آن است – این رویا به حقیقت پیوسته است. شما میتوانید اخبار را بر اساس تحلیل لحن(Sentiment Analysis) فیلتر کنید و فقط مواردی را که حس مثبتی منتقل میکنند به کاربر نشان دهید. در اینجا با استفاده از Aylien News API، یک فیلتر خبری هوشمند میسازیم.
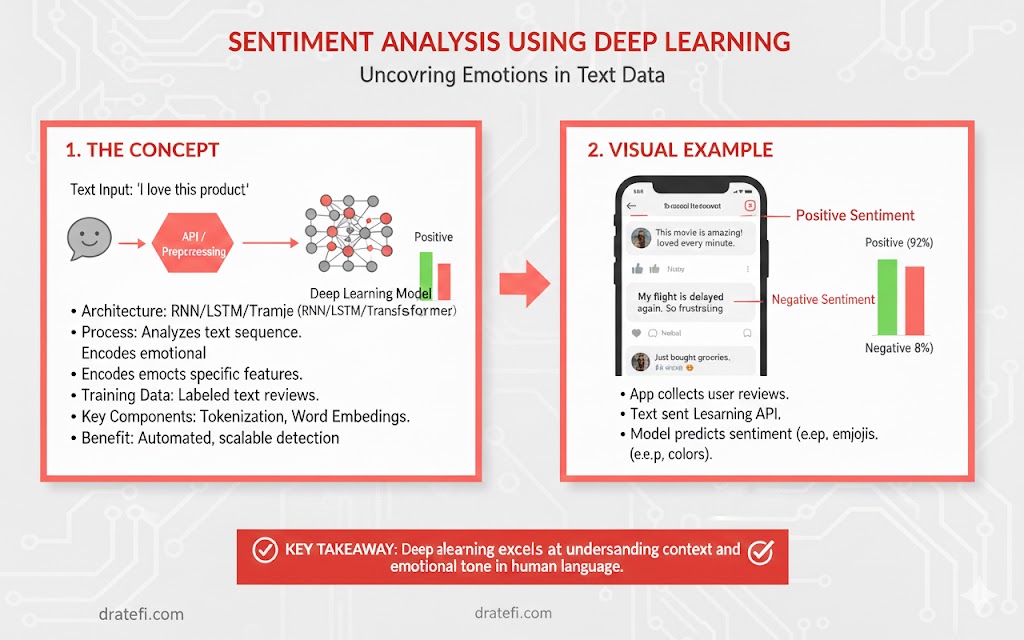
ملزومات و پیشنیازها
برای شروع به موارد زیر نیاز دارید:
- پایتون (Python): نسخه ۳.
- اتصال اینترنت: جهت فراخوانی API و دریافت اخبار از سرورهای. Aylien
راهنمای گامبهگام پیادهسازی
۱: ثبتنام و دریافت کلیدهای امنیتی
- ابتدا در وبسایت رسمی Aylien برای دریافت حساب کاربری ثبتنام کنید.
- پس از ورود به پنل کاربری، به بخش داشبورد بروید و دو مقدار مهم یعنی App_ID و API_key را کپی کرده و در جایی امن نگه دارید؛ اینها مجوز عبور برنامه شما هستند.
۲: نصب کتابخانه مورد نیاز
۳: کدنویسی و اجرا
# اگر روی Colab/Jupyter هستی اول این را اجرا کن (در یک سل جدا):
# !pip install aylien-news-api
import json
import aylien_news_api
from aylien_news_api.rest import ApiException
# 1) کلیدها را جایگزین کن
APP_ID = "YOUR_APP_ID"
API_KEY = "YOUR_API_KEY"
configuration = aylien_news_api.Configuration()
configuration.api_key["X-AYLIEN-NewsAPI-Application-ID"] = APP_ID
configuration.api_key["X-AYLIEN-NewsAPI-Application-Key"] = API_KEY
client = aylien_news_api.ApiClient(configuration)
api_instance = aylien_news_api.DefaultApi(client)
# 2) فیلترها (بدون published_at چون در SDK تو پشتیبانی نمیشود)
opts = {
"title": "technology",
"language": ["en"],
# بازه زمانی (در این SDK با start/end)
"published_at_start": "NOW-7DAYS",
"published_at_end": "NOW",
# فیلتر لحن مثبت (اگر اکانت/پلن sentiment را ندهد ممکن است 422 بدهد؛ در آن صورت این خط را کامنت کن)
"sentiment_body_polarity": "positive",
"sort_by": "published_at",
"per_page": 20,
"cursor": "*",
}
print("در حال استخراج اخبار...")
try:
api_response = api_instance.list_stories(**opts)
for story in api_response.stories:
print("-" * 60)
print("عنوان:", story.title)
print("منبع:", getattr(getattr(story, "source", None), "name", "N/A"))
print("تاریخ انتشار:", getattr(story, "published_at", "N/A"))
# sentiment ممکن است در پاسخ نباشد
s = getattr(story, "sentiment", None)
body = getattr(s, "body", None) if s else None
if body:
print("لحن:", body.polarity, "(score:", body.score, ")")
else:
print("لحن: در پاسخ موجود نیست")
# print("next cursor:", getattr(api_response, "next_page_cursor", None))
except ApiException as e:
print("خطای API:", e)
except Exception as e:
print("خطای غیرمنتظره:", e)
گام ۴: ذخیره و اجرا 💾
فایل را ذخیره کرده و در کنسول دستور python trial.py را اجرا کنید. خروجی شما شامل اطلاعاتی با فرمت JSON است که جزئیات دقیق خبر، نویسنده و تحلیل لحن را شامل میشود.
نتیجه شگفتانگیز: تصور کنید این سیستم را به یک چتبات یا دستیار صوتی مثل الکسا متصل کنید تا هر صبح فقط اخبار امیدبخش را برایتان بخواند! این قدرت یادگیری عمیق در شخصیسازی دنیای دیجیتال ماست.
اپلیکیشنهای متنباز (Open Source)
بهترین اتفاقی که در حال حاضر به پیشرفت جامعه محققان کمک میکند، طرز فکر متنباز است. پژوهشگران نتایج دستاوردهای خود را با بقیه به اشتراک میگذارند تا دانش یادگیری عمیق رشد کند و در نتیجه، این حوزه با سرعت خیرهکنندهای در حال گسترش است! در اینجا به برخی از مشارکتهای متنباز و نسخههای مختلفی که از مقالات پژوهشی استخراج شدهاند، اشاره میکنم.
مزایا
- قابلیت سفارشیسازی: چون کدها در دسترس هستند، میتوانید تمام جزئیات برنامه را ببینید و طبق نیاز خودتان آنها را تغییر دهید.
- همکاری جمعی: توسعهدهندگان زیادی با تجربیات متفاوت روی این پروژهها کار میکنند که باعث میشود نسخه نهایی بسیار بهتر از نسخه اولیه باشد. همچنین به دلیل استفاده مداوم کاربران، این برنامهها همیشه در حال تست شدن هستند و پایداری بالایی دارند.
معایب
- عدم مالکیت مشخص: چون سازمان خاصی پشت برخی از این پروژهها نیست، اگر مشکلی پیش بیاید، کسی مسئولیت آن را بر عهده نمیگیرد.
- مسائل لایسنس: محدودیتهای قانونی و کپیرایت ممکن است وجود داشته باشد و بسیاری از شرکتها تمایلی ندارند پروژههای خود را به صورت کاملاً آزاد منتشر کنند.
نکته: برای استفاده از برنامههای متنباز، همیشه توصیه میکنم به مخزن (Repository) رسمی آنها مراجعه کنید، زیرا برخی از آنها هنوز در مراحل اولیه هستند و ممکن است به دلایل نامشخصی دچار خطا شوند.
اصلاح جملات با یادگیری عمیق
امروزه سیستمها به راحتی غلطهای املایی را تشخیص میدهند، اما اصلاح خطاهای دستوری (Grammar) بسیار دشوارتر است. برای بهبود این وضعیت، میتوانیم از یادگیری عمیق کمک بگیریم. این پروژه (مخزن گیتهاب) دقیقاً تلاشی در همین راستا است.
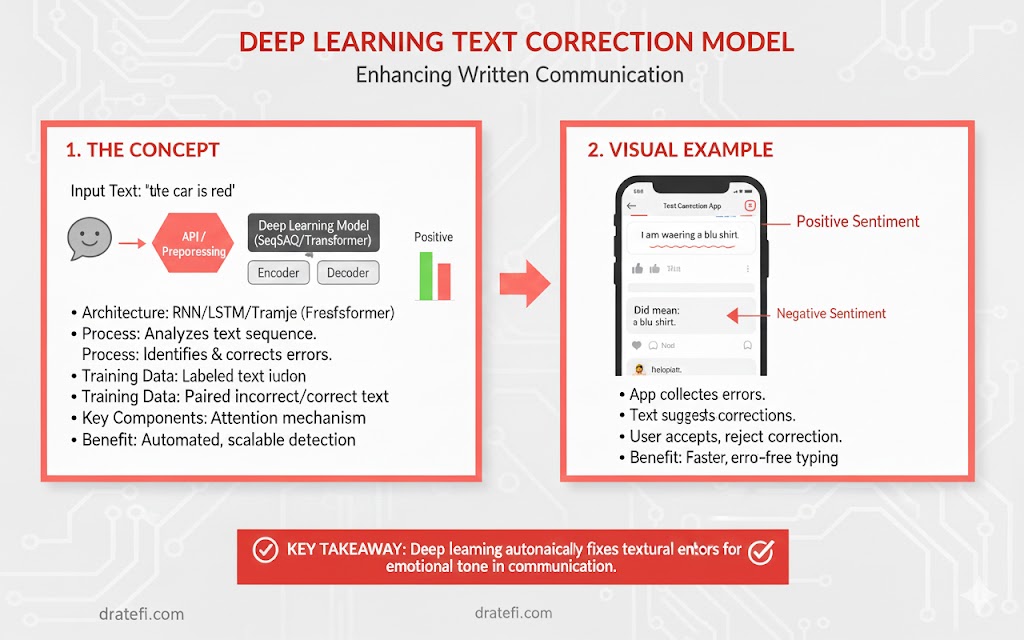
در اینجا یک شبکه عصبی پیشبینی توالی (Sequence Prediction) بر روی مجموعهای از جملات دارای غلط دستوری و نسخه اصلاح شده آنها آموزش دیده است. مدل آموزشدیده نتایج نویدبخشی را نشان میدهد:
- ورودی: ‘Kvothe went to market’
- خروجی: ‘Kvothe went to the market’
این مدل هنوز کامل نیست و در برخی جملات خطا دارد، اما با دادههای آموزشی بیشتر و الگوریتمهای کارآمدتر، نتایج قطعاً بهتر خواهد شد.
نیازمندیها:
- پایتون (نسخه ۳)
- پردازنده گرافیکی -(GPU) اختیاری، برای سرعت بیشتر در آموزش.
۱: نصب و آمادهسازی
- ابتدا TensorFlow را از وبسایت رسمی آن نصب کنید.
- سپس مخزن پروژه را از گیتهاب دانلود کرده و در سیستم خود ذخیره کنید:
- https://github.com/atpaino/deep-text-corrector
۲: دریافت دادهها
- مجموعه داده (Cornell Movie-Dialogs Corpus) را دانلود کرده و آن را در پوشه کاری خود استخراج (Extract) کنید.
۳: ساخت دادههای آموزشی
- با اجرای دستور زیر، فرآیند آمادهسازی دادهها برای آموزش مدل را آغاز کنید:
python preprocessors/preprocess_movie_dialogs.py --raw_data movie_lines.txt \
--out_file preprocessed_movie_lines.txt
و فایلهای آموزش (Train)، اعتبارسنجی (Validation) و تست (Test) را ایجاد کرده و آنها را در پوشه کاری فعلی خود ذخیره کنید.
۴:
حالا مدل یادگیری عمیق را با دستور زیر آموزش دهید:
python correct_text.py --train_path /movie_dialog_train.txt \
--val_path /movie_dialog_val.txt \
--config DefaultMovieDialogConfig \
--data_reader_type MovieDialogReader \
--model_path /movie_dialog_model
گام پنجم: مدل برای آموزش (Train) به زمان نیاز دارد. پس از اتمام فرآیند آموزش، میتوانید با دستور زیر آن را تست کنید:
python correct_text.py --test_path /movie_dialog_test.txt \
--config DefaultMovieDialogConfig \
--data_reader_type MovieDialogReader \
--model_path /movie_dialog_model \
--decode
تبدیل پرتره مرد به زن و برعکس
این یک اپلیکیشن واقعاً سرگرمکننده برای نشان دادن تواناییهای یادگیری عمیق است. در هسته اصلی، این برنامه از GAN (شبکه مولد رقابتی) استفاده میکند؛ نوعی از یادگیری عمیق که قادر است نمونههای کاملاً جدیدی را از خودش تولید کند.
نیازمندیها:
- پایتون (نسخه ۳.۵ به بالا)
- تنسورفلو
- پردازنده گرافیکی یا GPU (اختیاری، برای سرعت بیشتر در آموزش)
یک هشدار قبل از اجرا: اگر از GPU استفاده نمیکنید، آموزش این مدل زمان بسیار زیادی میبرد. حتی با یک کارت گرافیک ردهبالا (مثل Nvidia GeForce GTX 1080)، آموزش برای هر تصویر حدود ۲ ساعت زمان نیاز دارد.
۱: دانلود و آمادهسازی
- مخزن (Repository) پروژه را دانلود کرده و در سیستم خود استخراج کنید: https://github.com/david-gpu/deep-makeover
۲: دریافت مجموعه داده
- بخش Align&Cropped Images را از مجموعه داده CelebA دانلود کنید. یک پوشه به نام dataset بسازید و تمام تصاویر را در آن استخراج کنید.
۳: آموزش مدل
- با اجرای دستور زیر، فرآیند آموزش مدل را آغاز کنید:
python3 dm_main.py --run trainو سپس با ارسال تصویری که میخواهید تغییر دهید، آن را تست کنید:
python3 dm_main.py --run inference image.jpgساخت یک بات یادگیری تقویتشده عمیق برای بازی فلپی برد (Flappy Bird) 🐦🎮
احتمالاً در گذشته بازی فلپی برد را تجربه کردهاید. برای کسانی که نمیدانند، این یک بازی اندرویدی فوقالعاده اعتیادآور بود که هدف در آن، پرواز نگه داشتن پرنده در هوا با عبور از میان موانع و برخورد نکردن با آنها بود.
در این اپلیکیشن، یک بات مخصوص برای بازی فلپی برد با استفاده از تکنیکهای پیشرفته یادگیری تقویتشده (Reinforcement Learning) ساخته شده است. در اینجا میتوانید دمو و ویدیوی عملکرد یک بات آموزشدیده را مشاهده کنید:
یادگیری تقویتشده چیست؟
در این روش، ما به بات نمیگوییم دقیقاً چه کاری انجام دهد. در عوض، بات با “سعی و خطا” یاد میگیرد. اگر به لولهها برخورد کند، امتیاز منفی (جریمه) میگیرد و اگر زنده بماند، امتیاز مثبت (پاداش) دریافت میکند. به مرور زمان، بات یاد میگیرد که بهترین حرکت در هر لحظه چیست تا بیشترین پاداش را کسب کند.

نیازمندیهای سیستم:
برای اینکه بتوانید این پرنده هوشمند را به پرواز درآورید، به ابزارهای زیر نیاز دارید:
- پایتون: نسخه ۳
- تنسورفلو (Tensorflow): نسخه ۰.۷ به بالا (برای بخش هوش مصنوعی)
- پایگیم: (Pygame) (برای اجرای محیط بازی)
- OpenCV-Python: (برای پردازش فریمهای بازی)
پیادهسازی این پروژه بسیار ساده است، زیرا اکثر قطعات اصلی و پیچیده از قبل آماده شدهاند.
۱: دانلود مخزن رسمی
ابتدا کدهای پروژه را از مخزن رسمی گیتهاب (Official Repository) دانلود کرده و در سیستم خود استخراج کنید.
۲: نصب وابستگیها و اجرا
مطمئن شوید که تمام کتابخانههای ذکر شده در بالا را نصب کردهاید. پس از اطمینان، دستور زیر را در ترمینال یا کنسول خود اجرا کنید:
python deep_q_network.pyجدول مقایسهای پروژهها
برای اینکه بدانید کدام پروژه برای منابع سیستم شما مناسبتر است، این جدول را بررسی کنید:
| نام پروژه | منبع اصلی | نیاز به سختافزار (GPU) | هزینه/اعتبار | زمان اجرا |
| رنگی کردن عکس | Algorithmia API | اجرا در سرور | ۱۲ اعتبار/عکس | ثانیهای |
| چتبات هوشمند | Watson API | اجرا در سرور | رایگان (دوره ۳۰ روزه) | لحظهای |
| تحلیل اخبار | Aylien API | اجرا در سرور | رایگان (محدود) | ثانیهای |
| اصلاح متن | متنباز (GitHub) | اختیاری/توصیه شده | رایگان (Open Source) | زمانبر (آموزش مدل) |
| تبدیل پرتره (GAN) | متنباز (GitHub) | ضروری برای سرعت | رایگان (Open Source) | بسیار طولانی (۲ ساعت/عکس) |
| بات فلپی برد | متنباز (GitHub) | اختیاری | رایگان (Open Source) | بستگی به یادگیری بات |
جمع بندی
پروژههای معرفیشده در این مقاله نشان میدهند که شروع یادگیری عمیق لزوماً به دانش پیشرفته یا زیرساخت پیچیده نیاز ندارد. با استفاده از مدلهای آماده، کتابخانههای متنباز و ایدههای ساده، میتوان خیلی سریع اپلیکیشنهایی ساخت که هم آموزندهاند و هم کاربردی.
این ۶ اپلیکیشن، تنها نقطه شروع هستند. هدف اصلی آنها این است که شما را با مفاهیم پایه یادگیری عمیق، نحوه استفاده از مدلها و جریان کلی ساخت یک پروژه آشنا کنند. پس از اجرای این پروژهها، مسیر برای ساخت اپلیکیشنهای پیچیدهتر و شخصیسازیشده هموارتر خواهد شد.
در نهایت، بهترین راه یادگیری عمیق ساختن و تجربه کردن است. اگر مبتدی هستید، از پروژههای کوچک شروع کنید، از خطا نترسید و قدمبهقدم جلو بروید. همین پروژههای ساده میتوانند آغاز مسیر شما به سمت تسلط واقعی بر یادگیری عمیق باشند.



