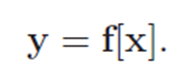فصل دوم
یادگیری تحت نظارت
یک مدل یادگیری نظارت شده، نقشه برداری از یک یا چند ورودی به یک یا چند خروجی را تعریف می کند. به عنوان مثال، ورودی ممکن است سن و مسافت پیموده شده یک تویوتا پریوس دست دوم باشد، و خروجی ممکن است ارزش تخمینی خودرو به دلار باشد.
مدل فقط یک معادله ریاضی است. هنگامی که ورودی ها از این معادله عبور می کنند، خروجی را محاسبه می کند و به آن استنتاج می گویند. معادله مدل نیز شامل پارامترهایی است. مقادیر پارامترهای مختلف نتیجه محاسبات را تغییر می دهد. معادله مدل خانواده ای از روابط احتمالی بین ورودی ها و خروجی ها را توصیف می کند و پارامترها رابطه خاص را مشخص می کنند.
وقتی مدلی را آموزش میدهیم یا یاد میگیریم، پارامترهایی را پیدا میکنیم که رابطه واقعی بین ورودیها و خروجیها را توصیف میکنند. یک الگوریتم یادگیری مجموعه آموزشی از جفت ورودی/خروجی را می گیرد و پارامترها را دستکاری می کند تا زمانی که ورودی ها خروجی های مربوطه خود را تا حد امکان پیش بینی کنند. اگر این مدل برای این جفتهای آموزشی خوب کار کند، امیدواریم برای ورودیهای جدید که خروجی واقعی ناشناخته است، پیشبینی خوبی انجام دهد.
هدف این فصل گسترش این ایده هاست. ابتدا، این چارچوب را به طور رسمی تر توصیف می کنیم و برخی از نمادها را معرفی می کنیم. سپس با یک مثال ساده کار می کنیم که در آن از یک خط مستقیم برای توصیف رابطه بین ورودی و خروجی استفاده می کنیم. این مدل خطی هم آشناست و هم به راحتی قابل تجسم است، اما با این وجود تمام ایده های اصلی یادگیری تحت نظارت را نشان می دهد.
2.1 مروری بر یادگیری تحت نظارت
در یادگیری نظارت شده، هدف ما ایجاد مدلی است که ورودی x را می گیرد و پیش بینی y را خروجی می کند. برای سادگی، فرض می کنیم که هر دو ورودی x و خروجی y بردارهایی با اندازه از پیش تعیین شده و ثابت هستند و عناصر هر بردار همیشه به یک شکل مرتب می شوند. در مثال پریوس بالا، ورودی x همیشه به ترتیب شامل سن خودرو و سپس مسافت پیموده شده است. این داده های ساختاری یا جدولی نامیده می شود.
برای پیشبینی، به یک مدل f[•] نیاز داریم که ورودی x را بگیرد و y را برگرداند، بنابراین:
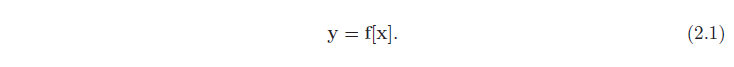
وقتی پیشبینی y را از ورودی x محاسبه میکنیم، این استنتاج را مینامیم.
مدل فقط یک معادله ریاضی با فرم ثابت است. نشان دهنده خانواده ای از روابط مختلف بین ورودی و خروجی است. این مدل همچنین شامل پارامترهای ϕ است. انتخاب پارامترها رابطه خاص بین ورودی و خروجی را تعیین می کند، بنابراین باید واقعاً بنویسیم:
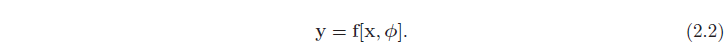
هنگامی که ما در مورد یادگیری یا آموزش یک مدل صحبت می کنیم، منظور ما این است که سعی می کنیم پارامترهایی را پیدا کنیم که پیش بینی های خروجی معقولی را از ورودی انجام می دهند. ما این پارامترها را با استفاده از مجموعه داده آموزشی از جفت I از نمونه های ورودی و خروجی xi, yi یاد می گیریم. هدف ما انتخاب پارامترهایی است که هر ورودی آموزشی را تا حد امکان به خروجی مرتبط با آن ترسیم می کند. ما درجه عدم تطابق در این نگاشت را با از دست دادن L کمی می کنیم. این یک مقدار اسکالر است که به طور خلاصه نشان می دهد که مدل چقدر خروجی های آموزشی را از ورودی های مربوطه خود برای پارامترهای ϕ پیش بینی ضعیفی می کند.
ما می توانیم از دست دادن را به عنوان یک تابع L[φ] از این پارامترها در نظر بگیریم. وقتی مدل را آموزش میدهیم، به دنبال پارامترهای ϕˆ هستیم که این تابع تلفات را به حداقل میرساند:
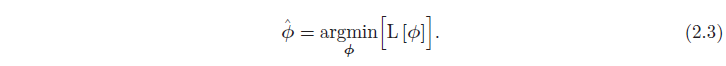
_به طور صحیح تر، تابع ضرر به داده های آموزشی {xi, yi} نیز بستگی دارد، بنابراین باید L [{xi, yi}، ϕ] را بنویسیم، اما این نسبتاً دست و پا گیر است._
اگر اتلاف پس از این به حداقل رساندن کوچک باشد، ما پارامترهای مدلی را پیدا کرده ایم که به طور دقیق خروجی های آموزشی yi را از ورودی های آموزشی xi پیش بینی می کند.
پس از آموزش یک مدل، اکنون باید عملکرد آن را ارزیابی کنیم. ما مدل را روی دادههای آزمون جداگانه اجرا میکنیم تا ببینیم چقدر به نمونههایی تعمیم مییابد که در طول آموزش مشاهده نکرده است. اگر عملکرد مناسب باشد، آنگاه ما آماده استقرار مدل هستیم.
2.2 مثال رگرسیون خطی
حالا بیایید این ایده ها را با یک مثال ساده عینی کنیم. ما یک مدل y = f[x, φ] را در نظر می گیریم که یک خروجی y را از یک ورودی x پیش بینی می کند. سپس یک تابع ضرر ایجاد می کنیم و در نهایت، آموزش مدل را مورد بحث قرار می دهیم.
2.2.1 مدل رگرسیون خطی 1 بعدی
یک مدل رگرسیون خطی 1 بعدی رابطه بین ورودی x و خروجی y را توصیف می کند به صورت خط مستقیم:
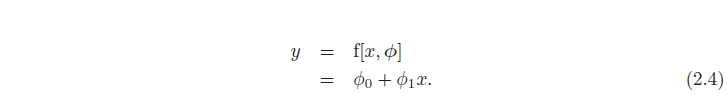
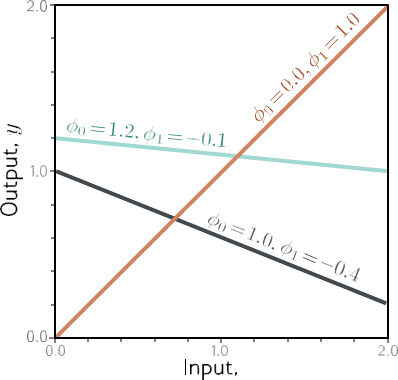
شکل 2.1 مدل رگرسیون خطی. برای انتخاب معینی از پارامترها ϕ = [ϕ0, φ1]T، مدل یک پیشبینی برای خروجی (محور y) بر اساس ورودی (محور x) انجام میدهد. انتخاب های مختلف برای عرض از مبدا ϕ0 و شیب ϕ1 این پیش بینی ها (خطوط فیروزه ای، نارنجی و خاکستری) را تغییر می دهند. مدل رگرسیون خطی (معادله 2.4) خانواده ای از روابط ورودی/خروجی (خطوط) را تعریف می کند و پارامترها عضو خانواده (خط خاص) را تعیین می کنند.
این مدل دارای دو پارامتر ϕ = [ϕ0, ϕ1]T است که ϕ0 نقطه قطع y خط و ϕ1 شیب است. انتخاب های مختلف برای مقطع و شیب y منجر به روابط متفاوتی بین ورودی و خروجی می شود (شکل 2.1). از این رو، معادله 2.4 خانواده ای از روابط ورودی-خروجی ممکن (همه خطوط ممکن) را تعریف می کند، و انتخاب پارامترها عضو این خانواده (خط خاص) را تعیین می کند.
2.2.2 ضرر
برای این مدل، مجموعه داده آموزشی (شکل 2.2a) شامل جفت ورودی/خروجی I xi, yi است. شکل های 2.2b-d سه خط را نشان می دهند که با سه مجموعه پارامتر تعریف شده اند. خط سبز در شکل 2.2d داده ها را با دقت بیشتری نسبت به دو مورد دیگر توصیف می کند زیرا به نقاط داده بسیار نزدیکتر است. با این حال، ما به یک رویکرد اصولی برای تصمیمگیری اینکه کدام پارامتر ϕ بهتر از سایرین است نیاز داریم. برای این منظور، به هر انتخاب از پارامترها یک مقدار عددی اختصاص میدهیم که میزان عدم تطابق بین مدل و دادهها را تعیین میکند. ما این مقدار را ضرر می نامیم. ضرر کمتر به معنای تناسب بهتر است.
عدم تطابق با انحراف بین پیشبینیهای مدل f[xi, φ] (ارتفاع خط در xi) و خروجیهای حقیقت زمینی yi ثبت میشود. این انحرافات به صورت خطوط چین نارنجی در شکل های 2.2b-d نشان داده شده اند. ما مجموع مجذورات این انحرافات را برای تمام جفتهای تمرین I محاسبه میکنیم.
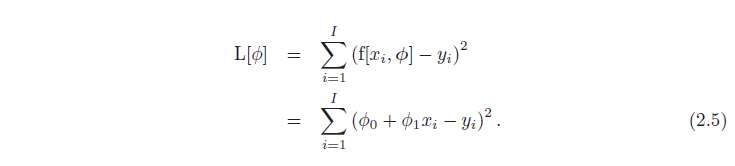
از آنجایی که بهترین پارامترها این عبارت را به حداقل میرسانند، آن را تلفات حداقل مربعات مینامیم. عمل مربع سازی به این معنی است که جهت انحراف (یعنی اینکه آیا خط است یا خیر
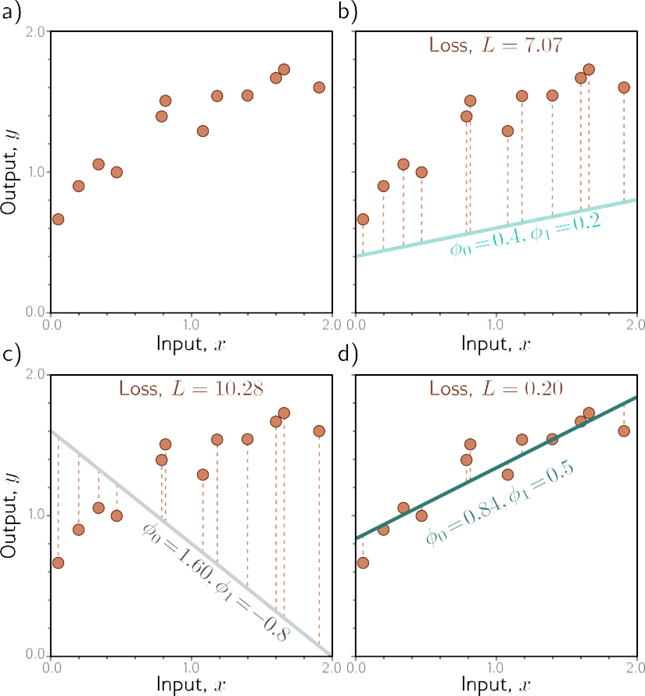
شکل 2.2داده های آموزش رگرسیون خطی، مدل و از دست دادن. الف) داده های آموزشی (نقاط نارنجی) شامل I = 12 جفت ورودی/خروجی xi, yi است. ب– د) هر پانل مدل رگرسیون خطی را با پارامترهای مختلف نشان می دهد. بسته به انتخاب پارامترهای عرض از مبدا و شیب خط ϕ = [ϕ0, φ1]T، خطاهای مدل (خطوط چین نارنجی) ممکن است بزرگتر یا کوچکتر باشند. ضرر L مجموع مجذورات این خطاها است. پارامترهایی که خطوط را در پانلهای (b) و (c) تعریف میکنند، به ترتیب 7.07 و L = 10.28 تلفات زیادی دارند، زیرا مدلها به خوبی تناسب دارند. افت L = 0.20 در پانل (d) کوچکتر است زیرا مدل به خوبی مطابقت دارد. در واقع، این کمترین تلفات را در بین تمام خطوط ممکن دارد، بنابراین اینها پارامتر بهینه هستند.
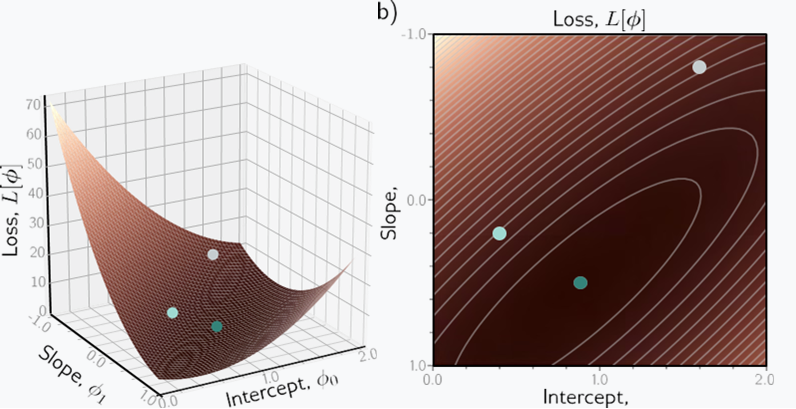
شکل 2.3 تابع ضرر برای مدل رگرسیون خطی با مجموعه داده در شکل 2.2a.
الف) هر ترکیبی از پارامترهای ϕ = [ϕ0,ϕ1]T یک تلفات مرتبط دارد. تابع تلفات حاصل L[φ] را می توان به عنوان یک سطح تجسم کرد. سه دایره نشان دهنده سه خط از شکل 2.2b–d هستند. ب) تلفات را می توان به عنوان یک نقشه حرارتی نیز مشاهده کرد، که در آن مناطق روشن تر نشان دهنده تلفات بزرگتر است. در اینجا ما مستقیماً به سطح در (a) از بالا نگاه می کنیم و بیضی های خاکستری نشان دهنده خطوط همسان هستند. بهترین خط برازش (شکل 2.2d) دارای پارامترهایی با کمترین تلفات است (دایره سبز).
بالاتر یا پایین تر از داده ها) مهم نیست. دلایل نظری نیز برای این انتخاب وجود دارد که در فصل 5 به آنها باز می گردیم.
تلفات L تابعی از پارامترهای ϕ است. وقتی مدل مناسب باشد بزرگتر خواهد شد ضعیف (شکل 2.2b،c) و کوچکتر زمانی که خوب است (شکل 2.2d). با توجه به این موضوع، ما L[φ] را تابع ضرر یا تابع هزینه میگوییم. هدف یافتن پارامترهای ϕˆ است که این کمیت را به حداقل می رساند:
تنها دو پارامتر وجود دارد (قطع y ϕ0 و شیب ϕ1)، بنابراین ما می توانیم تلفات را برای هر ترکیبی از مقادیر محاسبه کنیم و تابع تلفات را به عنوان یک سطح تجسم کنیم (شکل 2.3). “بهترین” پارامترها در حداقل این سطح هستند.
2.2.3 آموزش
فرآیند یافتن پارامترهایی که تلفات را به حداقل میرسانند، برازش مدل، آموزش یا یادگیری نامیده میشود. روش اصلی این است که پارامترهای اولیه را به صورت تصادفی انتخاب کنید و سپس با “پایین رفتن” تابع ضرر آنها را بهبود دهید تا زمانی که به پایین برسیم (شکل 2.4). یکی از راههای انجام این کار اندازهگیری گرادیان سطح در موقعیت فعلی و برداشتن گام در جهتی است که شدیدترین سرازیری است. سپس این روند را تا زمانی تکرار می کنیم که گرادیان صاف شود و دیگر نتوانیم پیشرفت کنیم.
2.2.4 تست
پس از آموزش این مدل، می خواهیم بدانیم که در دنیای واقعی چگونه عمل می کند. ما این کار را با محاسبه ضرر روی مجموعه جداگانه ای از داده های آزمایشی انجام می دهیم. میزان تعمیم دقت پیشبینی به دادههای آزمون تا حدی به میزان نماینده و کامل بودن دادههای آموزشی بستگی دارد. با این حال، این بستگی به میزان بیان مدل نیز دارد. یک مدل ساده مانند یک خط ممکن است نتواند رابطه واقعی بین ورودی و خروجی را نشان دهد. این به عنوان underfitting شناخته می شود. در مقابل، یک مدل بسیار گویا ممکن است ویژگی های آماری داده های آموزشی را توصیف کند که غیر معمول هستند و منجر به پیش بینی های غیر معمول می شوند. این به عنوان overfitting شناخته می شود.
2.3 خلاصه
یک مدل یادگیری نظارت شده یک تابع y = f[x, φ] است که ورودیهای x را به خروجیهای y مرتبط میکند. رابطه خاص توسط پارامترهای ϕ تعیین می شود. برای آموزش مدل، یک تابع ضرر L[φ] روی مجموعه داده آموزشی xi, yi تعریف می کنیم. این عدم تطابق بین پیشبینیهای مدل f[xi, φ] و خروجیهای مشاهدهشده yi را بهعنوان تابعی از پارامترهای φ نشان میدهد. سپس پارامترهایی را جستجو می کنیم که تلفات را به حداقل می رساند. ما مدل را روی مجموعه متفاوتی از دادههای آزمایشی ارزیابی میکنیم تا ببینیم چقدر به ورودیهای جدید تعمیم مییابد.
فصل های 3 تا 9 این ایده ها را گسترش می دهند. ابتدا به خود مدل می پردازیم. رگرسیون خطی 1 بعدی دارای این اشکال آشکار است که فقط می تواند رابطه بین ورودی و خروجی را به صورت یک خط مستقیم توصیف کند. شبکه های عصبی کم عمق (فصل 3) فقط کمی پیچیده تر از رگرسیون خطی هستند، اما خانواده بسیار بزرگتری از روابط ورودی/خروجی را توصیف می کنند. شبکه های عصبی عمیق (فصل 4) به همان اندازه گویا هستند اما می توانند توابع پیچیده را با پارامترهای کمتر توصیف کنند و در عمل بهتر عمل کنند.
فصل 5 به بررسی توابع ضرر برای وظایف مختلف می پردازد و زیربنای نظری تلفات حداقل مربعات را نشان می دهد. فصل 6 و 7 روند آموزش را مورد بحث قرار می دهد. فصل 8 چگونگی اندازه گیری عملکرد مدل را مورد بحث قرار می دهد. فصل 9 تکنیک های منظم سازی را بررسی می کند که هدف آنها بهبود عملکرد است.
(2این رویکرد تکراری در واقع برای مدل رگرسیون خطی ضروری نیست. در اینجا، امکان یافتن عبارات فرم بسته برای پارامترها وجود دارد. با این حال، این رویکرد نزولی گرادیان برای مدلهای پیچیدهتر کار میکند که در آن هیچ راهحل بستهای وجود ندارد و پارامترهای زیادی برای ارزیابی تلفات برای هر ترکیبی از مقادیر وجود دارد.)
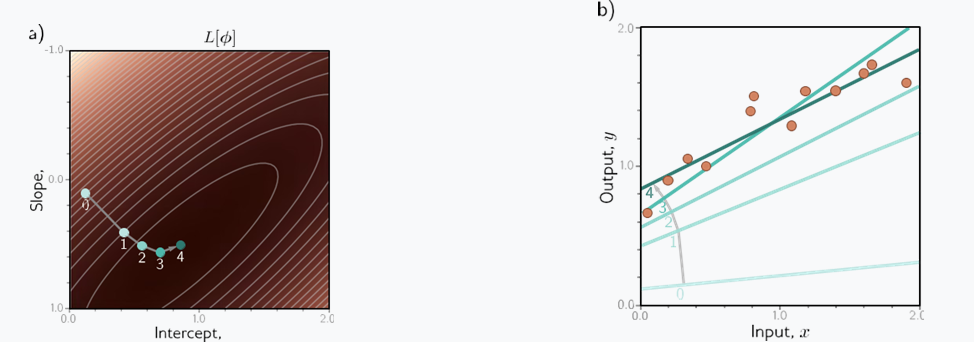
شکل 2.4
آموزش رگرسیون خطی. هدف این است که پارامترهای y-intercept و شیب را پیدا کنیم که با کمترین تلفات مطابقت دارد. الف) الگوریتمهای آموزشی تکراری پارامترها را بهطور تصادفی مقداردهی میکنند و سپس با «پیادهروی در سراشیبی» آنها را بهبود میبخشند تا زمانی که بهبود بیشتری حاصل نشود. در اینجا از موقعیت 0 شروع می کنیم و با فاصله معینی از سراشیبی (عمود بر خطوط) به موقعیت 1 حرکت می کنیم. سپس جهت سراشیبی را مجدداً محاسبه کرده و به موقعیت 2 می رویم. در نهایت به حداقل تابع (موقعیت 4) می رسیم. . ب) هر موقعیت 0-4 از پانل (الف) مربوط به یک عرض از مبدا و شیب y متفاوت است و بنابراین نشان دهنده یک خط متفاوت است. با کاهش تلفات، خطوط بیشتر با داده ها مطابقت دارند.
یادداشت ها
توابع ضرر در مقابل توابع هزینه:
در بسیاری از یادگیری ماشینی و در این کتاب، اصطلاحات تابع ضرر و تابع هزینه به جای یکدیگر استفاده می شوند. با این حال، به طور صحیح تر، یک تابع ضرر عبارت جداگانه ای است که با یک نقطه داده مرتبط است (به عنوان مثال، هر یک از عبارات مربع در سمت راست معادله 2.5)، و تابع هزینه مقدار کلی است که به حداقل می رسد (یعنی، تمام سمت راست معادله 2.5). یک تابع هزینه می تواند شامل اصطلاحات اضافی باشد که با نقاط داده فردی مرتبط نیستند (به بخش 9.1 مراجعه کنید). به طور کلی، تابع هدف هر تابعی است که قرار است به حداکثر یا حداقل برسد.
مدلهای مولد در مقابل مدلهای افتراقی:
مدلهای y = f[x, φ] در این فصل، مدلهای تمایزآمیز هستند. اینها یک پیشبینی خروجی y را از اندازهگیریهای دنیای واقعی x انجام میدهند. روش دیگر ساختن یک مدل مولد x = g[y, φ] است که در آن اندازهگیریهای دنیای واقعی x به عنوان تابعی از خروجی y محاسبه میشوند.
رویکرد مولد این عیب را دارد که مستقیماً y را پیشبینی نمیکند. برای انجام استنتاج، باید معادله تولیدی را به صورت y = g-1 [x, φ] معکوس کنیم، و این ممکن است دشوار باشد. با این حال، مدلهای تولیدی این مزیت را دارند که میتوانیم دانش قبلی در مورد نحوه ایجاد دادهها ایجاد کنیم. به عنوان مثال، اگر بخواهیم موقعیت و جهت سه بعدی y را پیش بینی کنیم از یک ماشین در تصویر x، سپس میتوانیم دانشی در مورد شکل ماشین، هندسه سه بعدی و انتقال نور در تابع x = g[y, φ] ایجاد کنیم.
این ایده خوبی به نظر می رسد، اما در واقع، مدل های تبعیض آمیز بر یادگیری ماشین مدرن غالب هستند. مزیت بهدستآمده از بهرهبرداری از دانش قبلی در مدلهای تولیدی معمولاً با یادگیری مدلهای متمایز بسیار انعطافپذیر با مقادیر زیادی از دادههای آموزشی مغلوب میشود.
مسائل
مسئله 2.1 برای راه رفتن در “سرازیری” روی تابع ضرر (معادله 2.5)، گرادیان آن را با توجه به پارامترهای ϕ0 و φ1 اندازه گیری می کنیم. عبارات شیب های ∂L/∂ϕ0 و ∂L/∂φ1 را محاسبه کنید.
مسئله 2.2 نشان می دهد که می توانیم با تنظیم عبارت مشتقات از مسئله 2.1 به صفر و حل ϕ0 و φ1، حداقل تابع ضرر را به صورت بسته پیدا کنیم. توجه داشته باشید که این برای رگرسیون خطی کار می کند اما برای مدل های پیچیده تر کار نمی کند. به همین دلیل است که ما از روش های برازش مدل تکراری مانند نزول گرادیان استفاده می کنیم (شکل 2.4).
مسئله 2.3* فرمول بندی مجدد رگرسیون خطی را به عنوان یک مدل مولد در نظر بگیرید، بنابراین x = g[y, ϕ] = ϕ0 + φ1y داریم. تابع ضرر جدید چیست؟ عبارتی برای تابع معکوس y = g−1[x, φ] پیدا کنید که برای انجام استنتاج از آن استفاده کنیم. آیا این مدل همان پیشبینیهای نسخه متمایز برای یک مجموعه داده آموزشی xi, yi را انجام میدهد؟ یکی از راههای ایجاد این امر، نوشتن کدی است که با استفاده از هر دو روش، یک خط را با سه نقطه داده متناسب کند و ببینید آیا نتیجه یکسان است یا خیر.