
مقدمه
در هر مدل یادگیری ماشین و یادگیری عمیق، یک سؤال اساسی وجود دارد:
مدل از کجا میفهمد که پیشبینیاش درست بوده یا اشتباه؟
پاسخ این سؤال در مفهومی کلیدی به نام تابع زیان (Loss Function) نهفته است.
تابع زیان معیاری است که میزان اختلاف بین خروجی پیشبینیشده مدل و مقدار واقعی را اندازهگیری میکند و به مدل نشان میدهد چقدر از هدف خود فاصله دارد. بدون تابع زیان، فرآیند یادگیری عملاً معنا ندارد؛ زیرا مدل هیچ معیاری برای اصلاح اشتباهات و بهبود عملکرد خود در اختیار نخواهد داشت.
در این مقاله، مفهوم تابع زیان را بهصورت گامبهگام بررسی میکنیم، تفاوت آن را در مسائل رگرسیون و طبقهبندی توضیح میدهیم و با معرفی پرکاربردترین توابع زیان، نشان میدهیم که چگونه انتخاب درست Loss Function میتواند نقش تعیینکنندهای در دقت، پایداری و موفقیت نهایی مدل داشته باشد.
اهداف آموزشی: در این مقاله چه میآموزیم؟
- نقش و اهمیت: درک جایگاه حیاتی توابع زیان در ارزیابی و سنجش عملکرد مدلهای یادگیری ماشین.
- تفاوتهای ساختاری: شناسایی و تمایز بین انواع مختلف توابع زیان که برای وظایف رگرسیون (Regression) و دستهبندی (Classification) طراحی شدهاند.
- توابع رگرسیون: یادگیری نحوه عملکرد و کاربرد توابع محبوبی مثل MSE (میانگین مربعات خطا)، MAE (میانگین قدر مطلق خطا) و Huber در مسائل پیشبینی عددی.
- توابع دستهبندی: کاوش در دنیای یادگیری عمیق با بررسی توابعی نظیر Binary Cross-Entropy (برای مسائل دو حالته) و Categorical Cross-Entropy (برای دستهبندیهای چندگانه).
- هدایت بهینهسازی: کشف اینکه چگونه توابع زیان از طریق تکنیکهایی مانند گرادیان کاهشی (Gradient Descent)، مسیر بهینهسازی مدل را هموار میکنند.
توابع زیان در یادگیری ماشین چه هستند؟
تابع زیان (Loss Function) به شما کمک میکند تا تعیین کنید الگوریتم شما با چه کیفیتی دادههای موجود را مدلسازی کرده است.به عبارت دیگر، «زیان» یا Loss معیاری است که مدل شما برای سنجش قابلیت پیشبینی و نزدیکی به نتایج مورد انتظار از آن استفاده میکند.
به طور کلی، توابع زیان بر اساس مسائل دنیای واقعی به دو دسته اصلی تقسیم میشوند:
- دستهبندی(Classification): در این مسائل، ما باید احتمال تعلق هر داده به یک کلاس یا طبقه خاص را پیشبینی کنیم.
- رگرسیون(Regression): در اینجا وظیفه مدل، پیشبینی یک مقدار عددی پیوسته بر اساس مجموعهای از ویژگیهای مستقل است.
تابع زیان در یادگیری عمیق
در تئوری تصمیمگیری و بهینهسازی ریاضی، تابع زیان (که گاهی تابع هزینه یا تابع خطا نیز نامیده میشود) تابعی است که یک رویداد یا مقادیر یک یا چند متغیر را به یک عدد حقیقی نگاشت میکند. این عدد در واقع نشاندهنده «هزینهای» است که با آن رویداد همراه است.

به زبان سادهتر:
تابع زیان روشی برای ارزیابی میزان موفقیت الگوریتم شما در مدلسازی مجموعه دادهها است.
این تابع در واقع یک فرمول ریاضی از پارامترهای الگوریتم یادگیری ماشین شماست.
کالبدشکافی تابع زیان در رگرسیون خطی
در یک مدل رگرسیون خطی ساده، پیشبینی با استفاده از پارامترهای شیب (m) و عرض از مبدأ (b) محاسبه میشود.
- تابع زیان در این حالت به صورت
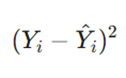
تعریف میشود.
- این یعنی تابع زیان مستقیماً تابعی از شیب و عرض از مبدأ است.
نقش توابع هدف در بهینهسازی
علاوه بر توابع زیان، توابع هدف (Objective Functions) نقش حیاتی در بهینهسازی مدلهای یادگیری ماشین ایفا میکنند.هدف نهایی در هر فرآیند آموزشی، به حداقل رساندن میزان زیان یا هزینه از طریق این توابع است تا مدل به بیشترین دقت ممکن برسد.
چرا این بخش برای یادگیری شما مهم است؟
همانطور که در فصل گرادیان کاهشی آموختید، این الگوریتم برای اینکه بداند به کدام سمت حرکت کند، به «شیب» تابع زیان نیاز دارد. بدون یک تابع زیان دقیق، مدل شما هرگز نمیفهمد که اشتباهاتش کجاست و چگونه باید پارامترهای خود را برای پیشبینیهای فردا اصلاح کند.
چرا تابع زیان (Loss Function) در یادگیری عمیق حیاتی است؟
در دنیای بهینهسازی ریاضی و تئوری تصمیمگیری، تابع زیان (که گاهی تابع هزینه یا تابع خطا نیز نامیده میشود) تابعی است که تفاوت بین پیشبینی مدل و واقعیت را به یک عدد حقیقی تبدیل میکند. این عدد در واقع نشاندهنده «هزینه» یا جریمهای است که مدل بابت اشتباهاتش پرداخت میکند.
نقش کلیدی توابع زیان در مدلهای هوش مصنوعی
- ارزیابی کیفیت مدل: تابع زیان روشی است برای سنجش اینکه الگوریتم شما چقدر خوب دادهها را مدلسازی کرده است.
- هدایت فرآیند آموزش: این توابع با کمیسازی خطاها، فرآیند آموزش را هدایت کرده و باعث بهروزرسانی دقیق پارامترها میشوند.
- پایه و اساس بهینهسازی: توابع زیان مبنای آموزش مدل هستند و به الگوریتمها جهت میدهند تا پارامترها را به سمتی تغییر دهند که دقت پیشبینی بهبود یابد.
توابع زیان رایج و کاربرد آنها
انتخاب تابع زیان درست، به ماهیت مسئله، توزیع دادهها و ویژگیهای مطلوب مدل بستگی دارد. در ادامه، مهمترین توابعی که در صنعت استفاده میشوند را بررسی میکنیم:
۱. توابع مخصوص رگرسیون (پیشبینی اعداد پیوسته)
- میانگین مربعات خطا (MSE): پرکاربردترین تابع در رگرسیون که میانگین مجذور تفاوتها را محاسبه میکند. این تابع خطاهای بزرگتر را به شدت جریمه میکند.
- میانگین قدر مطلق خطا(MAE): مجموع تفاوتهای مطلق را در نظر میگیرد و نسبت به MSE در برابر دادههای پرت مقاومتر است.
- Huber Loss: یک تابع هیبریدی که برای خطاهای کوچک به صورت مربعی (مثل MSE) و برای خطاهای بزرگ به صورت خطی (مثل MAE) عمل میکند؛ این ویژگی باعث پایداری و نرمی در بهروزرسانیهای گرادیان میشود.
۲. توابع مخصوص دستهبندی
- Cross-Entropy (Log Loss): حیاتیترین تابع برای مسائل دستهبندی در یادگیری عمیق. این تابع احتمالات پیشبینی شده را با برچسبهای واقعی مقایسه کرده و پیشبینیهای غلط را به شدت جریمه میکند.
- Binary Cross-Entropy: برای مسائل دو حالته (مثل اسپم یا غیر اسپم).
- Categorical Cross-Entropy: برای مسائل چند کلاسه (مثل تشخیص انواع اشیاء در تصویر).
- Hinge Loss: عمدتاً در آموزش طبقهبندهایی مثل SVM استفاده میشود و مدل را تشویق میکند که نه تنها درست حدس بزند، بلکه با حاشیه اطمینان بالا این کار را انجام دهد.
همکاری تابع زیان و گرادیان کاهشی
در طول فرآیند آموزش، الگوریتمهای یادگیری ماشین از تکنیکهای بهینهسازی مانند گرادیان کاهشی (Gradient Descent) استفاده میکنند تا تابع زیان را به حداقل برسانند.

- الگوریتم به صورت تکرارشونده پارامترها را بر اساس گرادیانِ تابع زیان تنظیم میکند.
- این حرکتِ گامبهگام تا رسیدن به راهکار بهینه ادامه مییابد تا مدل بتواند الگوهای پنهان در دادهها را به دقت استخراج کند.
توابع زیان در رگرسیون: آشنایی با میانگین مربعات خطا (MSE)
توابع زیان در مسائل رگرسیون (پیشبینی مقادیر عددی پیوسته) نقشی حیاتی ایفا میکنند. یکی از شناختهشدهترین و پرکاربردترینِ این توابع، میانگین مربعات خطا است که با نامهای دیگری مثل Squared Loss یا L2 Loss نیز شناخته میشود.
تعریف
تابع MSE یک روش مستقیم و بسیار کارآمد برای سنجش میزان دقت مدل است. همانطور که در بخشهای قبلی (گرادیان کاهشی) اشاره کردیم، این تابع تفاوت بین واقعیت و پیشبینی را به توان دو میرساند تا تصویری واضح از عملکرد مدل ارائه دهد.
نحوه محاسبه MSE در سه گام ساده:
برای محاسبه این مقدار، مراحل زیر طی میشود:
- محاسبه تفاوت: ابتدا اختلاف بین مقدار واقعی (Actual Value) و پیشبینی مدل را به دست میآوریم.
- مجذور کردن: این اختلاف را به توان دو میرسانیم (تا همواره عددی مثبت داشته باشیم و خطاهای بزرگتر با شدت بیشتری جریمه شوند).
- میانگینگیری: در نهایت، میانگین این مقادیر را برای کل مجموعه داده محاسبه میکنیم.
فرمول ریاضی تابع MSE:
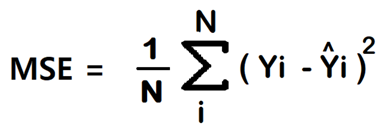
- ^Yi : خروجی پیشبینی شده توسط مدل.
- Yi: مقدار واقعی ثبت شده در دادهها.
چرا MSE در یادگیری عمیق محبوب است؟
این تابع به دلیل ویژگیهای ریاضی خود، برای الگوریتمهایی مثل گرادیان کاهشی بسیار ایدهآل است؛ زیرا یک منحنی نرم و “محدب” ایجاد میکند که پیدا کردن نقطه کمینه را برای مدل آسان میسازد.
مزایا
- تفسیر آسان: مفهوم MSE برای اکثر متخصصان و تحلیلگران داده بسیار ساده و قابل درک است.
- همواره مشتقپذیر: به دلیل وجود توان ۲، این تابع در تمام نقاط خود مشتقپذیر است. این ویژگی برای الگوریتمهایی مثل گرادیان کاهشی که به مشتق نیاز دارند، یک مزیت فنی بزرگ محسوب میشود.
معایب
- واحد اندازهگیری غیرملموس: خطا در MSE به صورت مجذور (توان ۲) محاسبه میشود. مثلاً اگر قیمت را پیشبینی میکنید، واحد خطا “تومان به توان ۲” خواهد بود که از نظر شهودی برای انسان کمی عجیب است.
- حساسیت شدید به دادههای پرت :MSE به دادههای پرت بسیار حساس است. چون خطاها به توان ۲ میرسند، یک داده بسیار غلط میتواند کل محاسبات مدل را تحت تأثیر قرار داده و آن را از مسیر درست منحرف کند.
تابع میانگین قدر مطلق خطا (MAE / L1 Loss)
اگر به دنبال راهکاری هستید که در برابر دادههای پرت مقاومتر باشد، MAE بهترین گزینه است.
MAE چیست؟
تابع میانگین قدر مطلق خطا یکی دیگر از توابع ساده اما بسیار قدرتمند است. این تابع به جای مجذور کردن تفاوتها، میانگینِ قدر مطلقِ (تفاوت بدون در نظر گرفتن علامت مثبت یا منفی) بین مقادیر واقعی و پیشبینیهای مدل را در کل مجموعه داده محاسبه میکند.
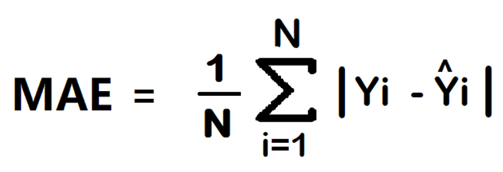
مزایا
درک شهودی و بسیار ساده: مفهوم قدر مطلق تفاوتها برای هر کسی، حتی بدون دانش ریاضی عمیق، قابل درک است.
- انطباق واحد خطا با خروجی: یکی از بزرگترین برتریهای MAE این است که واحد خطای آن دقیقاً با واحد ستون خروجی یکسان است.
- مثال: اگر مدل شما قیمت خانه را به “تومان” پیشبینی میکند، خطای MAE شما نیز به “تومان” خواهد بود. این برخلاف MSE است که خطا را به صورت “تومان به توان ۲” نشان میداد و تفسیر آن برای کارفرما یا کاربر نهایی دشوار بود.
- مقاومت در برابر دادههای پرت: MAE مانند یک فیلتر عمل میکند. اگر در دادههای شما چند رکورد کاملاً اشتباه (Outliers) وجود داشته باشد، MAE بر خلاف MSE تحت تأثیر شدید آنها قرار نمیگیرد و اجازه نمیدهد یک اشتباه بزرگ، کل یادگیری مدل را به انحراف بکشد.
معایب
- عدم مشتقپذیری در نقطه صفر: نمودار MAE در نقطه صفر دارای یک لبه تیز (V شکل) است. در ریاضیات، این یعنی تابع در این نقطه مشتقپذیر نیست.
- چالش برای گرادیان کاهشی: از آنجایی که الگوریتم گرادیان کاهشی برای حرکت نیاز به مشتق دارد، نمیتوان آن را مستقیماً روی MAE اعمال کرد.
- راهکار: مهندسان برای حل این مشکل از محاسبات زیر-گرادیان (Subgradient) استفاده میکنند تا بتوانند فرآیند بهینهسازی را ادامه دهند.
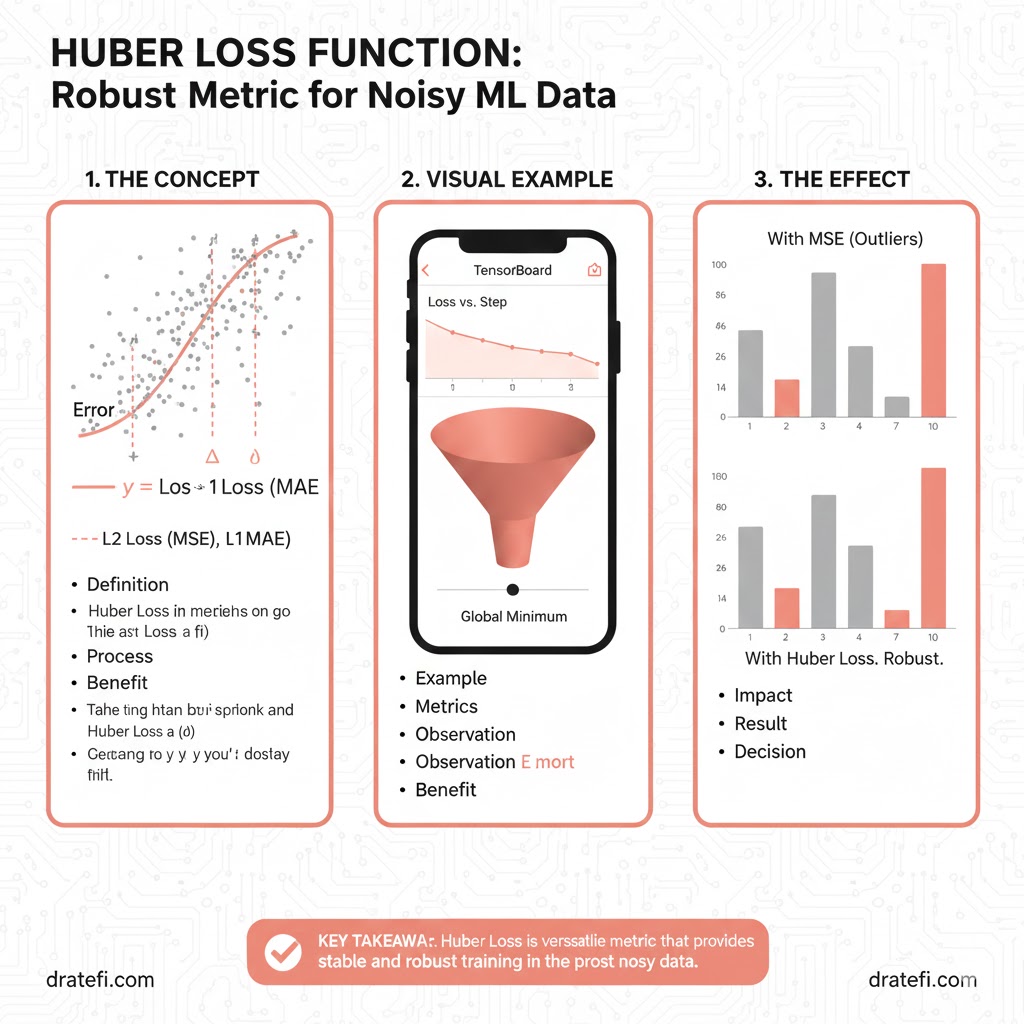
تابع زیان Huber: بهترینِ هر دو دنیا (Hybrid Solution)
وقتی نمیتوانید بین MSE و MAE یکی را انتخاب کنید، Huber Loss وارد میدان میشود.
Huber Loss چیست؟
این تابع در واقع یک ترکیب هوشمندانه است. Huber Loss برای خطاهای کوچک به صورت مربعی (مثل MSE) عمل میکند تا بهینهسازی نرمی داشته باشد، اما برای خطاهای بزرگ به صورت خطی (مثل MAE) تغییر رفتار میدهد تا در برابر دادههای پرت مقاوم بماند.
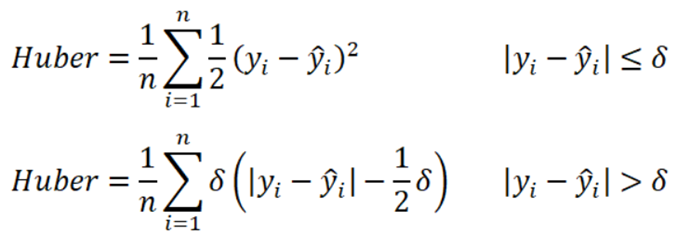
- y: مقدار واقعی یا همان حقیقت ماجرا.
- ^y: مقدار پیشبینی شدهای که مدل ما حدس زده است.
- δ (دلتا): این پارامتر در Huber Loss تعیین میکند که از چه نقطهای به بعد، رفتار تابع از حالت مربعی (MSE) به حالت خطی (MAE) تغییر کند.
چرا Huber Loss یک انتخاب هوشمندانه است؟
- مقاومت در برابر دادههای پرت: این تابع نسبت به MSE بسیار پایدارتر است و اجازه نمیدهد دادههای غلط مدل را منحرف کنند.
- تعادل عالی: این تابع در واقع نقطه تعادل بین دقتِ MAE و نرمیِ MSE است.
توابع زیان در دستهبندی: انتروپی متقاطع دوتایی (Binary Cross Entropy)
تا اینجا در مورد پیشبینی اعداد (مثل قیمت) صحبت کردیم. اما اگر بخواهیم بین دو گزینه انتخاب کنیم چه؟ مثلاً:
- آیا این بیمار کووید دارد یا خیر؟
- آیا این مقاله محبوب میشود یا خیر؟
اینجاست که Binary Cross Entropy یا همان Log Loss وارد میدان میشود.
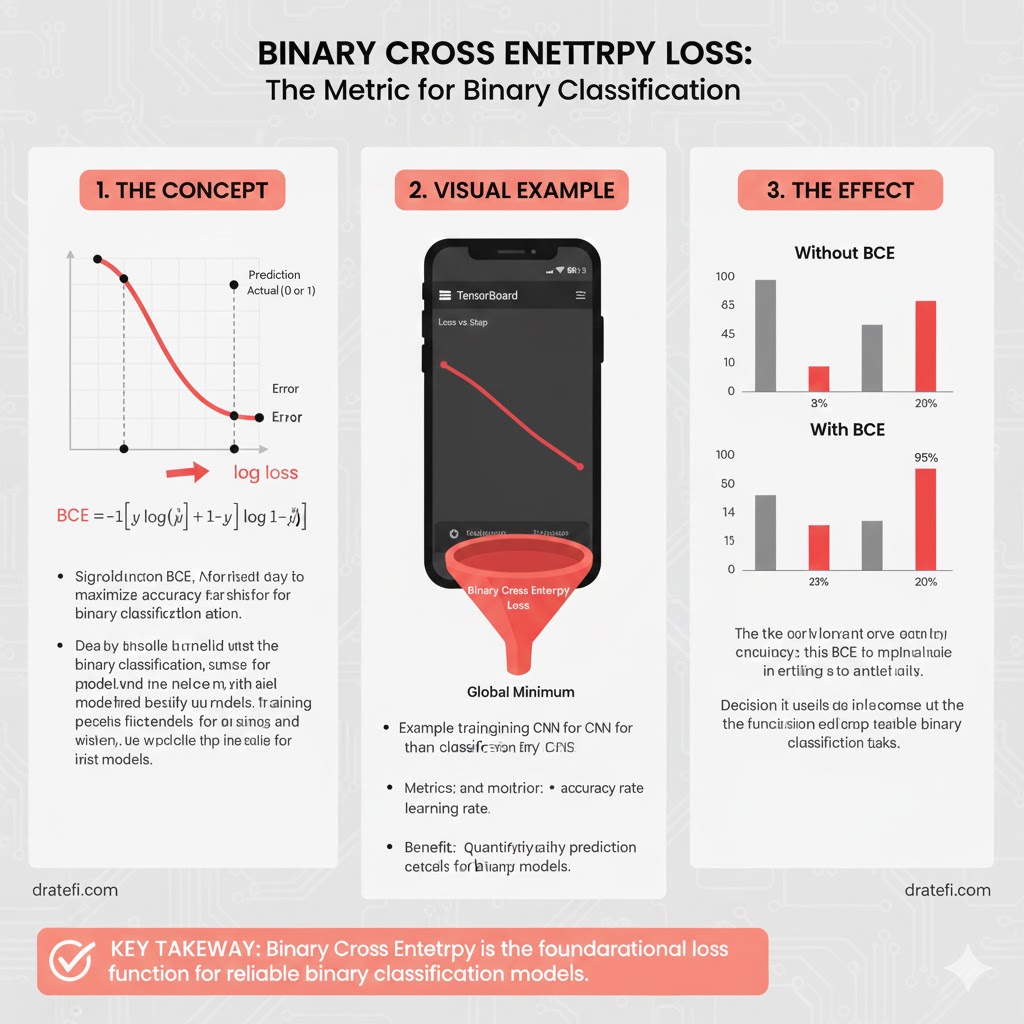
نحوه عملکرد
این تابع، احتمالات پیشبینی شده توسط مدل را با خروجی واقعی (که یا ۰ است یا ۱) مقایسه میکند.
- امتیازدهی تنبیهی: این تابع بر اساس “فاصله” پیشبینی شما از مقدار واقعی، مدل را جریمه میکند.
- مفهوم فاصله: یعنی هرچه مدل شما از واقعیت دورتر باشد (مثلاً مدل با اطمینان ۹۰٪ بگوید “بیمار نیست” در حالی که واقعیت “بیمار است” باشد)، Loss به صورت تصاعدی سنگینتر میشود.
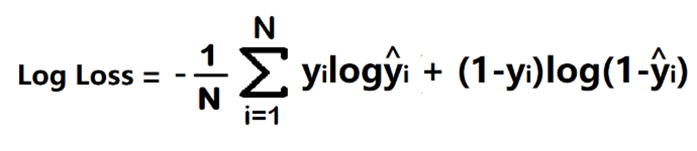
- yi: مقدار واقعی .
- ^y i : پیشبینی شبکه عصبی که نشاندهنده احتمال تخمینی برای هر کلاس است.
مزایا
- مشتقپذیری: توابع هزینه در دستهبندی معمولاً مشتقپذیر هستند. این ویژگی اجازه میدهد تا الگوریتمهایی مثل گرادیان کاهشی به راحتی پارامترها را بهروزرسانی کنند.
معایب
- کمینههای محلی متعدد: برخلاف رگرسیون خطی که یک کاسه صاف بود، در اینجا ممکن است با چندین “چاله” یا کمینه محلی روبرو شویم که مدل را در نقاط غیربهینه متوقف کند.
- عدم درک شهودی: برخلاف خطای MSE، درک معنای فیزیکی مقدار انتروپی متقاطع برای انسان دشوارتر است و بیشتر یک مفهوم آماری محسوب میشود.
مطالعه موردی: تشخیص اسپم در ایمیل
در یک سیستم تشخیص اسپم، مدل برای هر ایمیل یک احتمال (عددی بین ۰ تا ۱) تولید میکند.
- اگر احتمال نزدیک به ۱ باشد یعنی ایمیل اسپم است.
- اگر مدل برای یک ایمیلِ اسپم، احتمال ۰.۱ را بدهد، Log Loss خطای بسیار بزرگی را گزارش میکند تا گرادیان کاهشی بتواند وزنهای مدل را به سرعت اصلاح کند و در تکرار بعدی، این خطا تکرار نشود.
انتروپی متقاطع چندکلاسه (Categorical Cross Entropy)
زمانی که از مسائل سادهی دوحالته (مثل “بله” یا “خیر”) فراتر میرویم و به دنیای واقعی با احتمالات بیشمار پا میگذاریم، به ابزاری نیاز داریم که بتواند همزمان چندین دسته را مدیریت کند. اینجاست که Categorical Cross Entropy وارد میدان میشود.
این تابع زیان چه کاری انجام میدهد؟
تابع زیان برای مسائل دستهبندی چندکلاسه و رگرسیون سافتمکس طراحی شده است. تصور کنید میخواهید یک سیستم طراحی کنید که تصاویر حیوانات را به گروههای “سگ”، “گربه”، “اسب” و “پرنده” تقسیم کند؛ در اینجا شما با ۴ کلاس روبرو هستید و این تابع زیان به مدل شما یاد میدهد که چگونه احتمال درست را برای هر دسته پیدا کند.
کالبدشکافی فرمول ریاضی
برای درک بهتر، بیایید نگاهی به فرمول ریاضی این تابع بیندازیم:

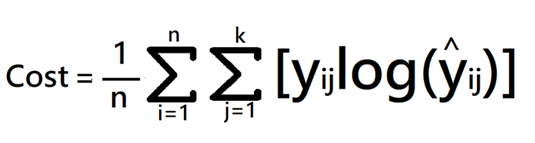
- k: نشاندهنده تعداد کل کلاسها یا دستههای موجود در مسئله است.
- y: مقدار واقعی یا برچسب صحیح داده که مدل باید به آن برسد.
- ^y: مقدار پیشبینی شده توسط شبکه عصبی (Neural Network Prediction) که بر اساس احتمالات بیان میشود.
کدام تابع زیان را انتخاب کنیم؟
انتخاب تابع زیان مناسب، به نوع دادهها و هدفی که در مدلسازی دنبال میکنید بستگی دارد. جدول زیر راهنمای سریعی برای تصمیمگیری شماست:
| نوع مسئله | تابع زیان (Loss Function) | مزیت اصلی | چالش کلیدی | بهترین کاربرد |
| رگرسیون | MSE (L2 Loss) | پایداری ریاضی و همگرایی سریع | حساسیت زیاد به دادههای پرت | پیشبینیهای دقیق عددی بدون نویز |
| رگرسیون | MAE (L1 Loss) | مقاومت بالا در برابر دادههای پرت (Robust) | عدم مشتقپذیری در نقطه صفر | دادههای دارای نویز و مقادیر دورافتاده |
| رگرسیون | Huber Loss | تعادل بین MSE و MAE | پیچیدگی در تنظیم پارامتر دلتا | مسائل رگرسیون مقاوم و صنعتی |
| دستهبندی دوتایی | Binary Cross-Entropy | جریمه تصادفی برای پیشبینیهای غلط | احتمال گیر افتادن در کمینههای محلی | تشخیص اسپم، بیماری (بله/خیر) |
| دستهبندی چندگانه | Categorical Cross-Entropy | مدیریت همزمان چندین کلاس | نیاز به کُدگذاری تک-فعال (One-Hot) | تشخیص اشیاء، میوهها، دستخط |
جمع بندی
تابع زیان یکی از حیاتیترین اجزای هر مدل یادگیری ماشین است که نقش «قطبنما» را در فرآیند آموزش ایفا میکند. این تابع به مدل نشان میدهد در هر مرحله تا چه اندازه به هدف نزدیک یا از آن دور شده است و مسیر اصلاح پارامترها را مشخص میکند.
در این مقاله دیدیم که هیچ تابع زیانی بهطور مطلق بهترین انتخاب نیست. هر Loss Function رفتار متفاوتی در برابر دادههای پرت، نویز و نوع مسئله دارد و انتخاب آن باید متناسب با هدف مدل، نوع داده و مسئله موردنظر انجام شود. بررسی توابعی مانند MSE، MAE، Huber و Cross-Entropy نشان داد که انتخاب نادرست تابع زیان میتواند حتی بهترین معماریها را به نتایج ضعیف برساند.
در نهایت، درک عمیق مفهوم تابع زیان، پیشنیاز فهم فرآیندهایی مانند گرادیان کاهشی (Gradient Descent) و پسانتشار (Backpropagation) است. این آگاهی به شما کمک میکند مدلها را نه بهصورت آزمونوخطا، بلکه با دیدی تحلیلی و مهندسی طراحی کنید و تصمیمهای دقیقتری در مسیر ساخت سیستمهای هوشمند بگیرید.



