تکنیکهای انتخاب ویژگی در یادگیری ماشین (Feature Selection Techniques)
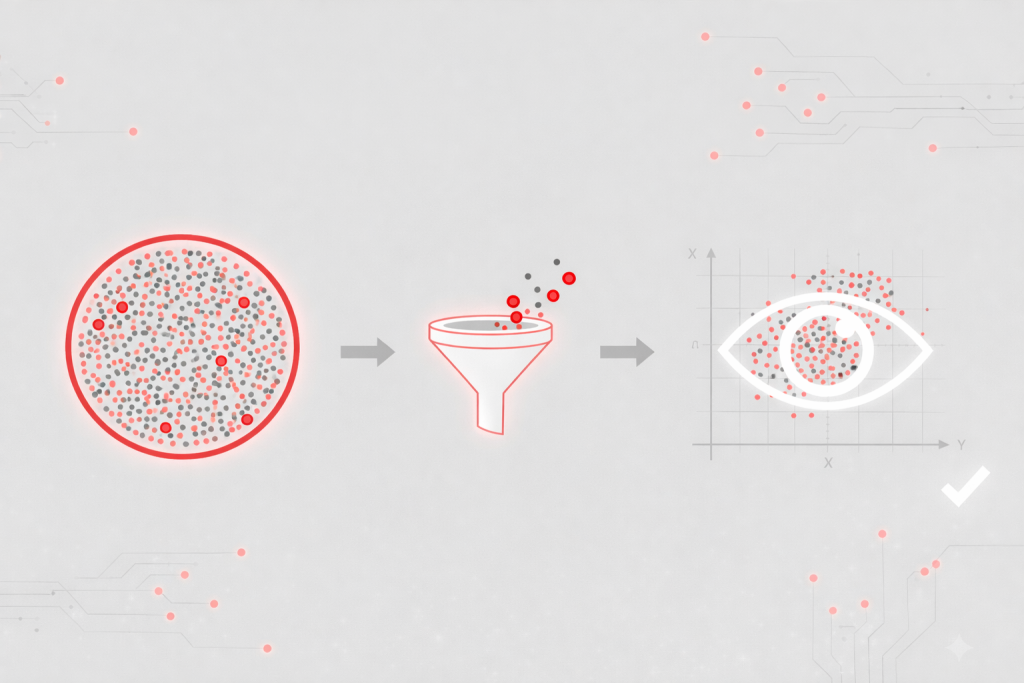
مقدمه در پروژههای یادگیری ماشین، همیشه «دادهی بیشتر» به معنای «مدل بهتر» نیست. در بسیاری از مواقع، وجود ویژگیهای زیاد، نامرتبط یا تکراری نهتنها کمکی به بهبود مدل نمیکند، بلکه باعث افزایش پیچیدگی، کاهش دقت و افت توان تعمیمپذیری میشود. اینجاست که انتخاب ویژگی (Feature Selection) بهعنوان یکی از مهمترین مراحل پیشپردازش دادهها مطرح میشود. […]
قسمت 5: استراتژیهای مدیریت (حذف، اصلاح یا نگهداری؟)

مقدمه شناسایی دادههای پرت فقط نیمی از مسیر است؛ تصمیمگیری درباره اینکه با این نقاط چه رفتاری داشته باشیم، بخش حساستر و تعیینکنندهتر ماجراست. یک انتخاب اشتباه—مثل حذف همه دادههای پرت—میتواند تحلیلها را منحرف کند، دقت مدلها را کاهش دهد یا حتی بخش مهمی از واقعیت داده را از بین ببرد.در این بخش به مهمترین […]
جعبهابزار تشخیص دادههای پرت (بخش اول): روشهای آماری، مقاوم و خوشهبندی

1.مقدمه تشخیص دادههای پرت یکی از حساسترین مراحل تحلیل داده و یادگیری ماشین است. انتخاب روش مناسب، مستقیم بر کیفیت مدل، دقت تحلیل و حتی تصمیمهای نهایی اثر میگذارد. اما مسئله فقط پیدا کردن چند مقدار عجیب نیست؛ بلکه انتخاب صحیح روش بر اساس نوع داده، فرضهای آماری، محدودیتهای محاسباتی و هدف نهایی پروژه است.در […]
تأثیرات دادههای پرت بر تحلیل آماری و مدل های یادگیری ماشین

مقدمه دادههای پرت (Outliers) همیشه بخشی از واقعیتهای یک دیتاست هستند. گاهی بیخطر و قابلچشمپوشی، گاهی هم مخرب و گمراهکننده است. اهمیت این دادهها فقط در مقدار غیرعادیشان نیست، بلکه در تأثیری است که میتوانند بر تحلیل، تصمیمگیری و مدلهای یادگیری ماشین داشته باشند. در این بخش بررسی میکنیم که دادههای پرت چگونه میتوانند نتایج […]
داده های پرت چیست؟کالبدشکافی Outlier ها از تعریف تا طبقهبندی

مقدمه دادههای پرت (Outliers) فقط چند عدد عجیبوغریب در جدول دادههای شما نیستند؛ آنها میتوانند یک خطای ویرانگر، نشانهای از یک مشکل پنهان یا حتی سرنخی برای یک کشف علمی بزرگ باشند. در سادهترین تعریف، دادهٔ پرت مشاهدهای است که رفتاری آنچنان متفاوت دارد که ما را به شک میاندازد: آیا واقعاً به همین مجموعه […]
مدیریت دادههای گمشده (Missing Data)

داده گمشده(Missing Value) چیست و چرا مهم است؟ در دنیای واقعی، دادهها هرگز تمیز و کامل نیستند. داده گمشده (Missing Value) به مقادیری اطلاق میشود که برای یک یا چند ویژگی (ستون) از یک یا چند مشاهده (سطر) در دسترس نیستند. این مقادیر گمشده، که اغلب با NULL، NaN (Not a Number)، ? یا یک […]
پاکسازی دادهها (Data Cleaning)

مقدمه در دنیای امروز که دادهها قلب تپندهی تحلیل، تصمیمگیری و توسعه سامانههای هوشمند هستند، کیفیت داده مهمتر از هر زمان دیگری شده است. حتی پیشرفتهترین مدلهای یادگیری ماشین نیز در صورتی که با دادههای ناقص، ناهماهنگ یا پرخطا تغذیه شوند، خروجی نادرست تولید میکنند. همین واقعیت، پاکسازی دادهها (Data Cleaning) را به یک گام […]
پیشپردازش دادهها چیست؟مراحل تکنیک ها و مثال ها

مقدمه در دنیای امروز که حجم عظیمی از دادهها از منابع مختلف تولید میشود، کیفیت و ساختار این دادهها نقش تعیینکنندهای در موفقیت تحلیلها و مدلهای دادهکاوی دارد. دادههای خام معمولاً شامل خطا، مقادیر گمشده، نویز، تناقض و ناهمگونی هستند؛ بنابراین قبل از هرگونه تحلیل، باید آنها را به شکل قابل اعتماد و ساختیافته […]
علم داده (Data Science)چیست؟

1. مقدمه در دنیای امروز که دادهها با سرعتی بيسابقه توليد ميشوند، علم داده (Data Science) به يكي از ستونهاي اصلي تصميمگيري هوشمند و مديريت كسبوكار تبديل شده است. سازمانها هر روز حجم عظيمي از دادههاي خام از پايگاههاي اطلاعاتي، سنسورها، شبكههاي اجتماعي و تعاملات مشتريان دريافت ميكنند. اما تنها زماني اين دادهها ارزشمند ميشوند […]
کدام الگوها جالب هستند؟ | فصل 4 (بخش سوم)
روشهای ارزیابی الگو اکثر الگوریتمهای کاوش قوانین ارتباط از یک چارچوب پشتیبانی-اطمینان استفاده میکنند. اگرچه حداقل آستانههای پشتیبانی و اطمینان به حذف یا حذف کاوش تعداد زیادی از قوانین غیرجذاب کمک میکنند، اما بسیاری از قوانین تولید شده هنوز برای بسیاری از کاربران جالب نیستند. این امر به ویژه هنگام کاوش در آستانههای پشتیبانی پایین […]